![]()
The term GF is used for different things:
This tutorial is primarily about the GF program and the GF programming language. It will guide you
A grammar is a definition of a language. From this definition, different language processing components can be derived:
A GF grammar can be seen as a declarative program from which these processing tasks can be automatically derived. In addition, many other tasks are readily available for GF grammars:
A typical GF application is based on a multilingual grammar involving translation on a special domain. Existing applications of this idea include
The specialization of a grammar to a domain makes it possible to obtain much better translations than in an unlimited machine translation system. This is due to the well-defined semantics of such domains. Grammars having this character are called application grammars. They are different from most grammars written by linguists just because they are multilingual and domain-specific.
However, there is another kind of grammars, which we call resource grammars. These are large, comprehensive grammars that can be used on any domain. The GF Resource Grammar Library has resource grammars for 10 languages. These grammars can be used as libraries to define application grammars. In this way, it is possible to write a high-quality grammar without knowing about linguistics: in general, to write an application grammar by using the resource library just requires practical knowledge of the target language.
This tutorial is mainly for programmers who want to learn to write application grammars. It will go through GF's programming concepts without entering too deep into linguistics. Thus it should be accessible to anyone who has some previous programming experience.
A separate document is being written on how to write resource grammars. This includes the ways in which linguistic problems posed by different languages are solved in GF.
The tutorial gives a hands-on introduction to grammar writing. We start by building a small grammar for the domain of food: in this grammar, you can say things like
this Italian cheese is delicious
in English and Italian.
The first English grammar
food.cf
is written in a context-free
notation (also known as BNF). The BNF format is often a good
starting point for GF grammar development, because it is
simple and widely used. However, the BNF format is not
good for multilingual grammars. While it is possible to
translate the words contained in a BNF grammar to another
language, proper translation usually involves more, e.g.
changing the word order in
Italian cheese ===> formaggio italiano
The full GF grammar format is designed to support such changes, by separating between the abstract syntax (the logical structure) and the concrete syntax (the sequence of words) of expressions.
There is more than words and word order that makes languages different. Words can have different forms, and which forms they have vary from language to language. For instance, Italian adjectives usually have four forms where English has just one:
delicious (wine | wines | pizza | pizzas)
vino delizioso, vini deliziosi, pizza deliziosa, pizze deliziose
The morphology of a language describes the forms of its words. While the complete description of morphology belongs to resource grammars, the tutorial will explain the main programming concepts involved. This will moreover make it possible to grow the fragment covered by the food example. The tutorial will in fact build a toy resource grammar in order to illustrate the module structure of library-based application grammar writing.
Thus it is by elaborating the initial food.cf example that
the tutorial makes a guided tour through all concepts of GF.
While the constructs of the GF language are the main focus,
also the commands of the GF system are introduced as they
are needed.
To learn how to write GF grammars is not the only goal of this tutorial. To learn the commands of the GF system means that simple applications of grammars, such as translation and quiz systems, can be built simply by writing scripts for the system. More complicated applications, such as natural-language interfaces and dialogue systems, also require programming in some general-purpose language. We will briefly explain how GF grammars are used as components of Haskell, Java, and Prolog grammars. The tutorial concludes with a couple of case studies showing how such complete systems can be built.
The program is open-source free software, which you can download via the
GF Homepage:
http://www.cs.chalmers.se/~aarne/GF
There you can download
If you want to compile GF from source, you need Haskell and Java compilers. But normally you don't have to compile, and you definitely don't need to know Haskell or Java to use GF.
To start the GF program, assuming you have installed it, just type
% gf
in the shell. You will see GF's welcome message and the prompt >.
The command
> help
will give you a list of available commands.
As a common convention in this Tutorial, we will use
% as a prompt that marks system commands
> as a prompt that marks GF commands
Thus you should not type these prompts, but only the lines that follow them.
Now you are ready to try out your first grammar.
We start with one that is not written in GF language, but
in the ubiquitous BNF notation (Backus Naur Form), which GF can also
understand. Type (or copy) the following lines in a file named
food.cf:
S ::= Item "is" Quality ;
Item ::= "this" Kind | "that" Kind ;
Kind ::= Quality Kind ;
Kind ::= "wine" | "cheese" | "fish" ;
Quality ::= "very" Quality ;
Quality ::= "fresh" | "warm" | "Italian" | "expensive" | "delicious" | "boring" ;
This grammar defines a set of phrases usable to speak about food.
It builds sentences (S) by assigning Qualities to
Items. The grammar shows a typical character of GF grammars:
they are small grammars describing some more or less well-defined
domain, such as in this case food.
The first GF command when using a grammar is to import it.
The command has a long name, import, and a short name, i.
You can type either
```> import food.cf
or
```> i food.cf
to get the same effect. The effect is that the GF program compiles your grammar into an internal representation, and shows a new prompt when it is ready.
You can now use GF for parsing:
> parse "this cheese is delicious"
S_Item_is_Quality (Item_this_Kind Kind_cheese) Quality_delicious
> p "that wine is very very Italian"
S_Item_is_Quality (Item_that_Kind Kind_wine)
(Quality_very_Quality (Quality_very_Quality Quality_Italian))
The parse (= p) command takes a string
(in double quotes) and returns an abstract syntax tree - the thing
beginning with S_Item_Is_Quality. We will see soon how to make sense
of the abstract syntax trees - now you should just notice that the tree
is different for the two strings.
Strings that return a tree when parsed do so in virtue of the grammar you imported. Try parsing something else, and you fail
> p "hello world"
No success in cf parsing hello world
no tree found
You can also use GF for linearizing
(linearize = l). This is the inverse of
parsing, taking trees into strings:
> linearize S_Item_is_Quality (Item_that_Kind Kind_wine) Quality_warm
that wine is warm
What is the use of this? Typically not that you type in a tree at
the GF prompt. The utility of linearization comes from the fact that
you can obtain a tree from somewhere else. One way to do so is
random generation (generate_random = gr):
> generate_random
S_Item_is_Quality (Item_this_Kind Kind_wine) Quality_delicious
Now you can copy the tree and paste it to the linearize command.
Or, more efficiently, feed random generation into linearization by using
a pipe.
> gr | l
this fresh cheese is delicious
The gibberish code with parentheses returned by the parser does not
look like trees. Why is it called so? Trees are a data structure that
represent nesting: trees are branching entities, and the branches
are themselves trees. Parentheses give a linear representation of trees,
useful for the computer. But the human eye may prefer to see a visualization;
for this purpose, GF provides the command visualizre_tree = vt, to which
parsing (and any other tree-producing command) can be piped:
parse "this delicious cheese is very Italian" | vt
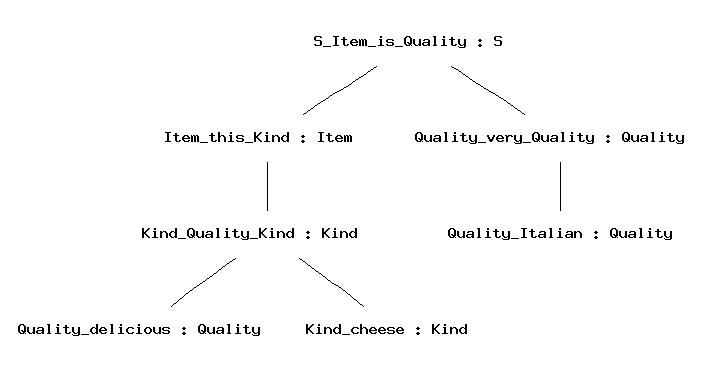
Random generation can be quite amusing. So you may want to generate ten strings with one and the same command:
> gr -number=10 | l
that wine is boring
that fresh cheese is fresh
that cheese is very boring
this cheese is Italian
that expensive cheese is expensive
that fish is fresh
that wine is very Italian
this wine is Italian
this cheese is boring
this fish is boring
To generate all sentence that a grammar
can generate, use the command generate_trees = gt.
> generate_trees | l
that cheese is very Italian
that cheese is very boring
that cheese is very delicious
that cheese is very expensive
that cheese is very fresh
...
this wine is expensive
this wine is fresh
this wine is warm
You get quite a few trees but not all of them: only up to a given
depth of trees. To see how you can get more, use the
help = h command,
help gt
Quiz. If the command gt generated all
trees in your grammar, it would never terminate. Why?
A pipe of GF commands can have any length, but the "output type" (either string or tree) of one command must always match the "input type" of the next command.
The intermediate results in a pipe can be observed by putting the
tracing flag -tr to each command whose output you
want to see:
> gr -tr | l -tr | p
S_Item_is_Quality (Item_this_Kind Kind_cheese) Quality_boring
this cheese is boring
S_Item_is_Quality (Item_this_Kind Kind_cheese) Quality_boring
This facility is good for test purposes: for instance, you may want to see if a grammar is ambiguous, i.e. contains strings that can be parsed in more than one way.
To save the outputs of GF commands into a file, you can
pipe it to the write_file = wf command,
> gr -number=10 | l | write_file exx.tmp
You can read the file back to GF with the
read_file = rf command,
> read_file exx.tmp | p -lines
Notice the flag -lines given to the parsing
command. This flag tells GF to parse each line of
the file separately. Without the flag, the grammar could
not recognize the string in the file, because it is not
a sentence but a sequence of ten sentences.
The syntax trees returned by GF's parser in the previous examples
are not so nice to look at. The identifiers of form Mks
are labels of the BNF rules. To see which label corresponds to
which rule, you can use the print_grammar = pg command
with the printer flag set to cf (which means context-free):
> print_grammar -printer=cf
S_Item_is_Quality. S ::= Item "is" Quality ;
Quality_Italian. Quality ::= "Italian" ;
Quality_boring. Quality ::= "boring" ;
Quality_delicious. Quality ::= "delicious" ;
Quality_expensive. Quality ::= "expensive" ;
Quality_fresh. Quality ::= "fresh" ;
Quality_very_Quality. Quality ::= "very" Quality ;
Quality_warm. Quality ::= "warm" ;
Kind_Quality_Kind. Kind ::= Quality Kind ;
Kind_cheese. Kind ::= "cheese" ;
Kind_fish. Kind ::= "fish" ;
Kind_wine. Kind ::= "wine" ;
Item_that_Kind. Item ::= "that" Kind ;
Item_this_Kind. Item ::= "this" Kind ;
A syntax tree such as
S_Item_is_Quality (Item_this_Kind Kind_wine) Quality_delicious
encodes the sequence of grammar rules used for building the
tree. If you look at this tree, you will notice that Item_this_Kind
is the label of the rule prefixing this to a Kind,
thereby forming an Item.
Kind_wine is the label of the kind "wine",
and so on. These labels are formed automatically when the grammar
is compiled by GF, in a way that guarantees that different rules
get different labels.
The labelled context-free grammar format permits user-defined
labels to each rule.
In files with the suffix .cf, you can prefix rules with
labels that you provide yourself - these may be more useful
than the automatically generated ones. The following is a possible
labelling of paleolithic.cf with nicer-looking labels.
Is. S ::= Item "is" Quality ;
That. Item ::= "that" Kind ;
This. Item ::= "this" Kind ;
QKind. Kind ::= Quality Kind ;
Cheese. Kind ::= "cheese" ;
Fish. Kind ::= "fish" ;
Wine. Kind ::= "wine" ;
Italian. Quality ::= "Italian" ;
Boring. Quality ::= "boring" ;
Delicious. Quality ::= "delicious" ;
Expensive. Quality ::= "expensive" ;
Fresh. Quality ::= "fresh" ;
Very. Quality ::= "very" Quality ;
Warm. Quality ::= "warm" ;
With this grammar, the trees look as follows:
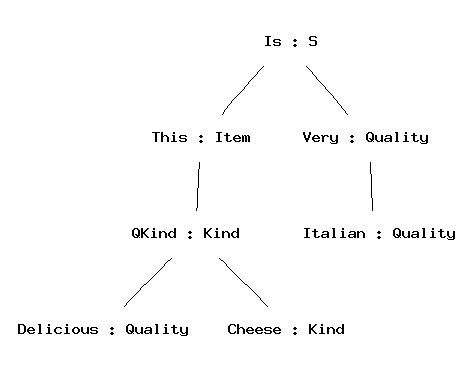
> parse -tr "this delicious cheese is very Italian" | vt
Is (This (QKind Delicious Cheese)) (Very Italian)
To see what there is in GF's shell state when a grammar
has been imported, you can give the plain command
print_grammar = pg.
> print_grammar
The output is quite unreadable at this stage, and you may feel happy that you did not need to write the grammar in that notation, but that the GF grammar compiler produced it.
However, we will now start the demonstration
how GF's own notation gives you
much more expressive power than the .cf
format. We will introduce the .gf format by presenting
one more way of defining the same grammar as in
food.cf.
Then we will show how the full GF grammar format enables you
to do things that are not possible in the weaker formats.
A GF grammar consists of two main parts:
The EBNF and CF formats fuse these two things together, but it is possible to take them apart. For instance, the sentence formation rule
Is. S ::= Item "is" Quality ;
is interpreted as the following pair of rules:
fun Is : Item -> Quality -> S ;
lin Is item quality = {s = item.s ++ "is" ++ quality.s} ;
The former rule, with the keyword fun, belongs to the abstract syntax.
It defines the function
Is which constructs syntax trees of form
(Is item quality).
The latter rule, with the keyword lin, belongs to the concrete syntax.
It defines the linearization function for
syntax trees of form (Is item quality).
Rules in a GF grammar are called judgements, and the keywords
fun and lin are used for distinguishing between two
judgement forms. Here is a summary of the most important
judgement forms:
| form | reading |
cat C |
C is a category |
fun f : A |
f is a function of type A |
| form | reading |
lincat C = T |
category C has linearization type T |
lin f = t |
function f has linearization t |
We return to the precise meanings of these judgement forms later. First we will look at how judgements are grouped into modules, and show how the paleolithic grammar is expressed by using modules and judgements.
A GF grammar consists of modules, into which judgements are grouped. The most important module forms are
abstract A = M, abstract syntax A with judgements in
the module body M.
concrete C of A = M, concrete syntax C of the
abstract syntax A, with judgements in the module body M.
The linearization type of a category is a record type, with zero of more fields of different types. The simplest record type used for linearization in GF is
{s : Str}
which has one field, with label s and type Str.
Examples of records of this type are
{s = "foo"}
{s = "hello" ++ "world"}
Whenever a record r of type {s : Str} is given,
r.s is an object of type Str. This is
a special case of the projection rule, allowing the extraction
of fields from a record:
{ ... p : T ... } then r.p : T
The type Str is really the type of token lists, but
most of the time one can conveniently think of it as the type of strings,
denoted by string literals in double quotes.
Notice that
"hello world"
is not recommended as an expression of type Str. It denotes
a token with a space in it, and will usually
not work with the lexical analysis that precedes parsing. A shorthand
exemplified by
["hello world and people"] === "hello" ++ "world" ++ "and" ++ "people"
can be used for lists of tokens. The expression
[]
denotes the empty token list.
To express the abstract syntax of food.cf in
a file Food.gf, we write two kinds of judgements:
cat judgement.
fun judgement,
with the type formed from the nonterminals of the rule.
abstract Food = {
cat
S ; Item ; Kind ; Quality ;
fun
Is : Item -> Quality -> S ;
This, That : Kind -> Item ;
QKind : Quality -> Kind -> Kind ;
Wine, Cheese, Fish : Kind ;
Very : Quality -> Quality ;
Fresh, Warm, Italian, Expensive, Delicious, Boring : Quality ;
}
Notice the use of shorthands permitting the sharing of
the keyword in subsequent judgements, and of the type
in subsequent fun judgements.
Each category introduced in Food.gf is
given a lincat rule, and each
function is given a lin rule. Similar shorthands
apply as in abstract modules.
concrete FoodEng of Food = {
lincat
S, Item, Kind, Quality = {s : Str} ;
lin
Is item quality = {s = item.s ++ "is" ++ quality.s} ;
This kind = {s = "this" ++ kind.s} ;
That kind = {s = "that" ++ kind.s} ;
QKind quality kind = {s = quality.s ++ kind.s} ;
Wine = {s = "wine"} ;
Cheese = {s = "cheese"} ;
Fish = {s = "fish"} ;
Very quality = {s = "very" ++ quality.s} ;
Fresh = {s = "fresh"} ;
Warm = {s = "warm"} ;
Italian = {s = "Italian"} ;
Expensive = {s = "expensive"} ;
Delicious = {s = "delicious"} ;
Boring = {s = "boring"} ;
}
Module name + .gf = file name
Each module is compiled into a .gfc file.
Import FoodEng.gf and see what happens
> i FoodEng.gf
The GF program does not only read the file
FoodEng.gf, but also all other files that it
depends on - in this case, Food.gf.
For each file that is compiled, a .gfc file
is generated. The GFC format (="GF Canonical") is the
"machine code" of GF, which is faster to process than
GF source files. When reading a module, GF decides whether
to use an existing .gfc file or to generate
a new one, by looking at modification times.
The main advantage of separating abstract from concrete syntax is that one abstract syntax can be equipped with many concrete syntaxes. A system with this property is called a multilingual grammar.
Multilingual grammars can be used for applications such as
translation. Let us buid an Italian concrete syntax for
Food and then test the resulting
multilingual grammar.
concrete FoodIta of Food = {
lincat
S, Item, Kind, Quality = {s : Str} ;
lin
Is item quality = {s = item.s ++ "�" ++ quality.s} ;
This kind = {s = "questo" ++ kind.s} ;
That kind = {s = "quello" ++ kind.s} ;
QKind quality kind = {s = kind.s ++ quality.s} ;
Wine = {s = "vino"} ;
Cheese = {s = "formaggio"} ;
Fish = {s = "pesce"} ;
Very quality = {s = "molto" ++ quality.s} ;
Fresh = {s = "fresco"} ;
Warm = {s = "caldo"} ;
Italian = {s = "italiano"} ;
Expensive = {s = "caro"} ;
Delicious = {s = "delizioso"} ;
Boring = {s = "noioso"} ;
}
Import the two grammars in the same GF session.
> i FoodEng.gf
> i FoodIta.gf
Try generation now:
> gr | l
quello formaggio molto noioso � italiano
> gr | l -lang=FoodEng
this fish is warm
Translate by using a pipe:
> p -lang=FoodEng "this cheese is very delicious" | l -lang=FoodIta
questo formaggio � molto delizioso
The lang flag tells GF which concrete syntax to use in parsing and
linearization. By default, the flag is set to the last-imported grammar.
To see what grammars are in scope and which is the main one, use the command
print_options = po:
> print_options
main abstract : Food
main concrete : FoodIta
actual concretes : FoodIta FoodEng
If translation is what you want to do with a set of grammars, a convenient
way to do it is to open a translation_session = ts. In this session,
you can translate between all the languages that are in scope.
A dot . terminates the translation session.
> ts
trans> that very warm cheese is boring
quello formaggio molto caldo � noioso
that very warm cheese is boring
trans> questo vino molto italiano � molto delizioso
questo vino molto italiano � molto delizioso
this very Italian wine is very delicious
trans> .
>
This is a simple language exercise that can be automatically
generated from a multilingual grammar. The system generates a set of
random sentences, displays them in one language, and checks the user's
answer given in another language. The command translation_quiz = tq
makes this in a subshell of GF.
> translation_quiz FoodEng FoodIta
Welcome to GF Translation Quiz.
The quiz is over when you have done at least 10 examples
with at least 75 % success.
You can interrupt the quiz by entering a line consisting of a dot ('.').
this fish is warm
questo pesce � caldo
> Yes.
Score 1/1
this cheese is Italian
questo formaggio � noioso
> No, not questo formaggio � noioso, but
questo formaggio � italiano
Score 1/2
this fish is expensive
You can also generate a list of translation exercises and save it in a
file for later use, by the command translation_list = tl
> translation_list -number=25 FoodEng FoodIta
The number flag gives the number of sentences generated.
The module system of GF makes it possible to extend a
grammar in different ways. The syntax of extension is
shown by the following example. We extend Food by
adding a category of questions and two new functions.
abstract Morefood = Food ** {
cat
Question ;
fun
QIs : Item -> Quality -> Question ;
Pizza : Kind ;
}
Parallel to the abstract syntax, extensions can be built for concrete syntaxes:
concrete MorefoodEng of Morefood = FoodEng ** {
lincat
Question = {s : Str} ;
lin
QIs item quality = {s = "is" ++ item.s ++ quality.s} ;
Pizza = {s = "pizza"} ;
}
The effect of extension is that all of the contents of the extended and extending module are put together.
Specialized vocabularies can be represented as small grammars that only do "one thing" each. For instance, the following are grammars for fruit and mushrooms
abstract Fruit = {
cat Fruit ;
fun Apple, Peach : Fruit ;
}
abstract Mushroom = {
cat Mushroom ;
fun Cep, Agaric : Mushroom ;
}
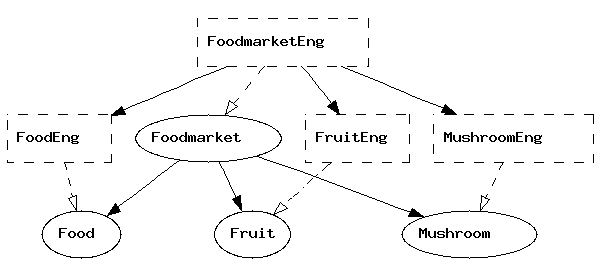
They can afterwards be combined into bigger grammars by using multiple inheritance, i.e. extension of several grammars at the same time:
abstract Foodmarket = Food, Fruit, Mushroom ** {
fun
FruitKind : Fruit -> Kind ;
MushroomKind : Mushroom -> Kind ;
}
At this point, you would perhaps like to go back to
Food and take apart Wine to build a special
Drink module.
When you have created all the abstract syntaxes and
one set of concrete syntaxes needed for Foodmarket,
your grammar consists of eight GF modules. To see how their
dependences look like, you can use the command
visualize_graph = vg,
> visualize_graph
and the graph will pop up in a separate window.
The graph uses
To document your grammar, you may want to print the
graph into a file, e.g. a .png file that
can be included in an HTML document. You can do this
by first printing the graph into a file .dot and then
processing this file with the dot program.
> pm -printer=graph | wf Foodmarket.dot
> ! dot -Tpng Foodmarket.dot > Foodmarket.png
The latter command is a Unix command, issued from GF by using the
shell escape symbol !. The resulting graph was shown in the previous section.
The command print_multi = pm is used for printing the current multilingual
grammar in various formats, of which the format -printer=graph just
shows the module dependencies. Use the help to see what other formats
are available:
> help pm
> help -printer
In comparison to the .cf format, the .gf format still looks rather
verbose, and demands lots more characters to be written. You have probably
done this by the copy-paste-modify method, which is a standard way to
avoid repeating work.
However, there is a more elegant way to avoid repeating work than the copy-and-paste method. The golden rule of functional programming says that
A function separates the shared parts of different computations from the changing parts, parameters. In functional programming languages, such as Haskell, it is possible to share muc more than in the languages such as C and Java.
GF is a functional programming language, not only in the sense that
the abstract syntax is a system of functions (fun), but also because
functional programming can be used to define concrete syntax. This is
done by using a new form of judgement, with the keyword oper (for
operation), distinct from fun for the sake of clarity.
Here is a simple example of an operation:
oper ss : Str -> {s : Str} = \x -> {s = x} ;
The operation can be applied to an argument, and GF will compute the application into a value. For instance,
ss "boy" ---> {s = "boy"}
(We use the symbol ---> to indicate how an expression is
computed into a value; this symbol is not a part of GF)
Thus an oper judgement includes the name of the defined operation,
its type, and an expression defining it. As for the syntax of the defining
expression, notice the lambda abstraction form \x -> t of
the function.
Operator definitions can be included in a concrete syntax. But they are not really tied to a particular set of linearization rules. They should rather be seen as resources usable in many concrete syntaxes.
The resource module type can be used to package
oper definitions into reusable resources. Here is
an example, with a handful of operations to manipulate
strings and records.
resource StringOper = {
oper
SS : Type = {s : Str} ;
ss : Str -> SS = \x -> {s = x} ;
cc : SS -> SS -> SS = \x,y -> ss (x.s ++ y.s) ;
prefix : Str -> SS -> SS = \p,x -> ss (p ++ x.s) ;
}
Resource modules can extend other resource modules, in the same way as modules of other types can extend modules of the same type. Thus it is possible to build resource hierarchies.
Any number of resource modules can be
opened in a concrete syntax, which
makes definitions contained
in the resource usable in the concrete syntax. Here is
an example, where the resource StringOper is
opened in a new version of FoodEng.
concrete Food2Eng of Food = open StringOper in {
lincat
S, Item, Kind, Quality = SS ;
lin
Is item quality = cc item (prefix "is" quality) ;
This = prefix "this" ;
That = prefix "that" ;
QKind = cc ;
Wine = ss "wine" ;
Cheese = ss "cheese" ;
Fish = ss "fish" ;
Very = prefix "very" ;
Fresh = ss "fresh" ;
Warm = ss "warm" ;
Italian = ss "Italian" ;
Expensive = ss "expensive" ;
Delicious = ss "delicious" ;
Boring = ss "boring" ;
}
The same string operations could be use to write FoodIta
more concisely.
Using operations defined in resource modules is a way to avoid repetitive code. In addition, it enables a new kind of modularity and division of labour in grammar writing: grammarians familiar with the linguistic details of a language can put this knowledge available through resource grammar modules, whose users only need to pick the right operations and not to know their implementation details.
Suppose we want to say, with the vocabulary included in
Food.gf, things like
all Italian wines are delicious
The new grammatical facility we need are the plural forms of nouns and verbs (wines, are), as opposed to their singular forms.
The introduction of plural forms requires two things:
Different languages have different rules of inflection and agreement. For instance, Italian has also agreement in gender (masculine vs. feminine). We want to express such special features of languages in the concrete syntax while ignoring them in the abstract syntax.
To be able to do all this, we need one new judgement form and many new expression forms. We also need to generalize linearization types from strings to more complex types.
We define the parameter type of number in Englisn by using a new form of judgement:
param Number = Sg | Pl ;
To express that Kind expressions in English have a linearization
depending on number, we replace the linearization type {s : Str}
with a type where the s field is a table depending on number:
lincat Kind = {s : Number => Str} ;
The table type Number => Str is in many respects similar to
a function type (Number -> Str). The main difference is that the
argument type of a table type must always be a parameter type. This means
that the argument-value pairs can be listed in a finite table. The following
example shows such a table:
lin Cheese = {s = table {
Sg => "cheese" ;
Pl => "cheeses"
}
} ;
The application of a table to a parameter is done by the selection
operator !. For instance,
Cheese.s ! Pl
is a selection, whose value is "cheeses".
All English common nouns are inflected in number, most of them in the same way: the plural form is formed from the singular form by adding the ending s. This rule is an example of a paradigm - a formula telling how the inflection forms of a word are formed.
From GF point of view, a paradigm is a function that takes a lemma -
a string also known as a dictionary form - and returns an inflection
table of desired type. Paradigms are not functions in the sense of the
fun judgements of abstract syntax (which operate on trees and not
on strings), but operations defined in oper judgements.
The following operation defines the regular noun paradigm of English:
oper regNoun : Str -> {s : Number => Str} = \x -> {
s = table {
Sg => x ;
Pl => x + "s"
}
} ;
The gluing operator + tells that
the string held in the variable x and the ending "s"
are written together to form one token. Thus, for instance,
(regNoun "cheese").s ! Pl ---> "cheese" + "s" ---> "cheeses"
Some English nouns, such as mouse, are so irregular that
it makes no sense to see them as instances of a paradigm. Even
then, it is useful to perform data abstraction from the
definition of the type Noun, and introduce a constructor
operation, a worst-case macro for nouns:
oper mkNoun : Str -> Str -> Noun = \x,y -> {
s = table {
Sg => x ;
Pl => y
}
} ;
Thus we could define
lin Mouse = mkNoun "mouse" "mice" ;
and
oper regNoun : Str -> Noun = \x ->
mkNoun x (x + "s") ;
instead of writing the inflection table explicitly.
The grammar engineering advantage of worst-case macros is that
the author of the resource module may change the definitions of
Noun and mkNoun, and still retain the
interface (i.e. the system of type signatures) that makes it
correct to use these functions in concrete modules. In programming
terms, Noun is then treated as an abstract datatype.
In addition to the completely regular noun paradigm regNoun,
some other frequent noun paradigms deserve to be
defined, for instance,
sNoun : Str -> Noun = \kiss -> mkNoun kiss (kiss + "es") ;
What about nouns like fly, with the plural flies? The already available solution is to use the longest common prefix fl (also known as the technical stem) as argument, and define
yNoun : Str -> Noun = \fl -> mkNoun (fl + "y") (fl + "ies") ;
But this paradigm would be very unintuitive to use, because the technical stem
is not an existing form of the word. A better solution is to use
the lemma and a string operator init, which returns the initial segment (i.e.
all characters but the last) of a string:
yNoun : Str -> Noun = \fly -> mkNoun fly (init fly + "ies") ;
The operator init belongs to a set of operations in the
resource module Prelude, which therefore has to be
opened so that init can be used.
It may be hard for the user of a resource morphology to pick the right
inflection paradigm. A way to help this is to define a more intelligent
paradigm, which chooses the ending by first analysing the lemma.
The following variant for English regular nouns puts together all the
previously shown paradigms, and chooses one of them on the basis of
the final letter of the lemma (found by the prelude operator last).
regNoun : Str -> Noun = \s -> case last s of {
"s" | "z" => mkNoun s (s + "es") ;
"y" => mkNoun s (init s + "ies") ;
_ => mkNoun s (s + "s")
} ;
This definition displays many GF expression forms not shown befores; these forms are explained in the next section.
The paradigms regNoun does not give the correct forms for
all nouns. For instance, mouse - mice and
fish - fish must be given by using mkNoun.
Also the word boy would be inflected incorrectly; to prevent
this, either use mkNoun or modify
regNoun so that the "y" case does not
apply if the second-last character is a vowel.
Expressions of the table form are built from lists of
argument-value pairs. These pairs are called the branches
of the table. In addition to constants introduced in
param definitions, the left-hand side of a branch can more
generally be a pattern, and the computation of selection is
then performed by pattern matching:
_ matches anything
"s", matches the same string
P | ... | Q matches anything that
one of the disjuncts matches
Pattern matching is performed in the order in which the branches appear in the table: the branch of the first matching pattern is followed.
As syntactic sugar, one-branch tables can be written concisely,
\\P,...,Q => t === table {P => ... table {Q => t} ...}
Finally, the case expressions common in functional
programming languages are syntactic sugar for table selections:
case e of {...} === table {...} ! e
A common idiom is to
gather the oper and param definitions
needed for inflecting words in
a language into a morphology module. Here is a simple
example, MorphoEng.
--# -path=.:prelude
resource MorphoEng = open Prelude in {
param
Number = Sg | Pl ;
oper
Noun, Verb : Type = {s : Number => Str} ;
mkNoun : Str -> Str -> Noun = \x,y -> {
s = table {
Sg => x ;
Pl => y
}
} ;
regNoun : Str -> Noun = \s -> case last s of {
"s" | "z" => mkNoun s (s + "es") ;
"y" => mkNoun s (init s + "ies") ;
_ => mkNoun s (s + "s")
} ;
mkVerb : Str -> Str -> Verb = \x,y -> mkNoun y x ;
regVerb : Str -> Verb = \s -> case last s of {
"s" | "z" => mkVerb s (s + "es") ;
"y" => mkVerb s (init s + "ies") ;
"o" => mkVerb s (s + "es") ;
_ => mkVerb s (s + "s")
} ;
}
The first line gives as a hint to the compiler the
search path needed to find all the other modules that the
module depends on. The directory prelude is a subdirectory of
GF/lib; to be able to refer to it in this simple way, you can
set the environment variable GF_LIB_PATH to point to this
directory.
To test a resource module independently, you can import it
with a flag that tells GF to retain the oper definitions
in the memory; the usual behaviour is that oper definitions
are just applied to compile linearization rules
(this is called inlining) and then thrown away.
> i -retain MorphoEng.gf
The command compute_concrete = cc computes any expression
formed by operations and other GF constructs. For example,
> cc regVerb "echo"
{s : Number => Str = table Number {
Sg => "echoes" ;
Pl => "echo"
}
}
The command show_operations = so` shows the type signatures
of all operations returning a given value type:
> so Verb
MorphoEng.mkNoun : Str -> Str -> {s : {MorphoEng.Number} => Str}
MorphoEng.mkVerb : Str -> Str -> {s : {MorphoEng.Number} => Str}
MorphoEng.regNoun : Str -> {s : {MorphoEng.Number} => Str}
MorphoEng.regVerb : Str -> { s : {MorphoEng.Number} => Str}
Why does the command also show the operations that form
Nouns? The reason is that the type expression
Verb is first computed, and its value happens to be
the same as the value of Noun.
We can now enrich the concrete syntax definitions to comprise morphology. This will involve a more radical variation between languages (e.g. English and Italian) then just the use of different words. In general, parameters and linearization types are different in different languages - but this does not prevent the use of a common abstract syntax.
The rule of subject-verb agreement in English says that the verb phrase must be inflected in the number of the subject. This means that a noun phrase (functioning as a subject), inherently has a number, which it passes to the verb. The verb does not have a number, but must be able to receive whatever number the subject has. This distinction is nicely represented by the different linearization types of noun phrases and verb phrases:
lincat NP = {s : Str ; n : Number} ;
lincat VP = {s : Number => Str} ;
We say that the number of NP is an inherent feature,
whereas the number of NP is parametric.
The agreement rule itself is expressed in the linearization rule of the predication structure:
lin PredVP np vp = {s = np.s ++ vp.s ! np.n} ;
The following section will present
FoodsEng, assuming the abstract syntax Foods
that is similar to Food but also has the
plural determiners These and Those.
The reader is invited to inspect the way in which agreement works in
the formation of sentences.
The grammar uses both
Prelude and
MorphoEng.
We will later see how to make the grammar even
more high-level by using a resource grammar library
and parametrized modules.
--# -path=.:resource:prelude
concrete FoodsEng of Foods = open Prelude, MorphoEng in {
lincat
S, Quality = SS ;
Kind = {s : Number => Str} ;
Item = {s : Str ; n : Number} ;
lin
Is item quality = ss (item.s ++ (mkVerb "are" "is").s ! item.n ++ quality.s) ;
This = det Sg "this" ;
That = det Sg "that" ;
These = det Pl "these" ;
Those = det Pl "those" ;
QKind quality kind = {s = \\n => quality.s ++ kind.s ! n} ;
Wine = regNoun "wine" ;
Cheese = regNoun "cheese" ;
Fish = mkNoun "fish" "fish" ;
Very = prefixSS "very" ;
Fresh = ss "fresh" ;
Warm = ss "warm" ;
Italian = ss "Italian" ;
Expensive = ss "expensive" ;
Delicious = ss "delicious" ;
Boring = ss "boring" ;
oper
det : Number -> Str -> Noun -> {s : Str ; n : Number} = \n,d,cn -> {
s = d ++ cn.s ! n ;
n = n
} ;
}
The reader familiar with a functional programming language such as
Haskell must have noticed the similarity
between parameter types in GF and algebraic datatypes (data definitions
in Haskell). The GF parameter types are actually a special case of algebraic
datatypes: the main restriction is that in GF, these types must be finite.
(It is this restriction that makes it possible to invert linearization rules into
parsing methods.)
However, finite is not the same thing as enumerated. Even in GF, parameter constructors can take arguments, provided these arguments are from other parameter types - only recursion is forbidden. Such parameter types impose a hierarchic order among parameters. They are often needed to define the linguistically most accurate parameter systems.
To give an example, Swedish adjectives
are inflected in number (singular or plural) and
gender (uter or neuter). These parameters would suggest 2*2=4 different
forms. However, the gender distinction is done only in the singular. Therefore,
it would be inaccurate to define adjective paradigms using the type
Gender => Number => Str. The following hierarchic definition
yields an accurate system of three adjectival forms.
param AdjForm = ASg Gender | APl ;
param Gender = Utr | Neutr ;
Here is an example of pattern matching, the paradigm of regular adjectives.
oper regAdj : Str -> AdjForm => Str = \fin -> table {
ASg Utr => fin ;
ASg Neutr => fin + "t" ;
APl => fin + "a" ;
}
A constructor can have patterns as arguments. For instance, the adjectival paradigm in which the two singular forms are the same, can be defined
oper plattAdj : Str -> AdjForm => Str = \platt -> table {
ASg _ => platt ;
APl => platt + "a" ;
}
Even though in GF morphology
is mostly seen as an auxiliary of syntax, a morphology once defined
can be used on its own right. The command morpho_analyse = ma
can be used to read a text and return for each word the analyses that
it has in the current concrete syntax.
> rf bible.txt | morpho_analyse
In the same way as translation exercises, morphological exercises can
be generated, by the command morpho_quiz = mq. Usually,
the category is set to be something else than S. For instance,
> i lib/resource/french/VerbsFre.gf
> morpho_quiz -cat=V
Welcome to GF Morphology Quiz.
...
r�appara�tre : VFin VCondit Pl P2
r�apparaitriez
> No, not r�apparaitriez, but
r�appara�triez
Score 0/1
Finally, a list of morphological exercises and save it in a
file for later use, by the command morpho_list = ml
> morpho_list -number=25 -cat=V
The number flag gives the number of exercises generated.
A linearization type may contain more strings than one. An example of where this is useful are English particle verbs, such as switch off. The linearization of a sentence may place the object between the verb and the particle: he switched it off.
The first of the following judgements defines transitive verbs as discontinuous constituents, i.e. as having a linearization type with two strings and not just one. The second judgement shows how the constituents are separated by the object in complementization.
lincat TV = {s : Number => Str ; part : Str} ;
lin PredTV tv obj = {s = \\n => tv.s ! n ++ obj.s ++ tv.part} ;
There is no restriction in the number of discontinuous constituents
(or other fields) a lincat may contain. The only condition is that
the fields must be of finite types, i.e. built from records, tables,
parameters, and Str, and not functions. A mathematical result
about parsing in GF says that the worst-case complexity of parsing
increases with the number of discontinuous constituents. Moreover,
the parsing and linearization commands only give reliable results
for categories whose linearization type has a unique Str valued
field labelled s.
Local definitions ("let expressions") are used in functional
programming for two reasons: to structure the code into smaller
expressions, and to avoid repeated computation of one and
the same expression. Here is an example, from
``MorphoIta:
oper regNoun : Str -> Noun = \vino ->
let
vin = init vino ;
o = last vino
in
case o of {
"a" => mkNoun Fem vino (vin + "e") ;
"o" | "e" => mkNoun Masc vino (vin + "i") ;
_ => mkNoun Masc vino vino
} ;
Sometimes there are many alternative ways to define a concrete syntax.
For instance, the verb negation in English can be expressed both by
does not and doesn't. In linguistic terms, these expressions
are in free variation. The variants construct of GF can
be used to give a list of strings in free variation. For example,
NegVerb verb = {s = variants {["does not"] ; "doesn't} ++ verb.s ! Pl} ;
An empty variant list
variants {}
can be used e.g. if a word lacks a certain form.
In general, variants should be used cautiously. It is not
recommended for modules aimed to be libraries, because the
user of the library has no way to choose among the variants.
Moreover, even though variants admits lists of any type,
its semantics for complex types can cause surprises.
Record types and records can be extended with new fields. For instance,
in German it is natural to see transitive verbs as verbs with a case.
The symbol ** is used for both constructs.
lincat TV = Verb ** {c : Case} ;
lin Follow = regVerb "folgen" ** {c = Dative} ;
To extend a record type or a record with a field whose label it already has is a type error.
A record type T is a subtype of another one R, if T has all the fields of R and possibly other fields. For instance, an extension of a record type is always a subtype of it.
If T is a subtype of R, an object of T can be used whenever an object of R is required. For instance, a transitive verb can be used whenever a verb is required.
Contravariance means that a function taking an R as argument can also be applied to any object of a subtype T.
Product types and tuples are syntactic sugar for record types and records:
T1 * ... * Tn === {p1 : T1 ; ... ; pn : Tn}
<t1, ..., tn> === {p1 = T1 ; ... ; pn = Tn}
Thus the labels p1, p2,...` are hard-coded.
The construct exemplified in
oper artIndef : Str =
pre {"a" ; "an" / strs {"a" ; "e" ; "i" ; "o"}} ;
Thus
artIndef ++ "cheese" ---> "a" ++ "cheese"
artIndef ++ "apple" ---> "an" ++ "cheese"
This very example does not work in all situations: the prefix u has no general rules, and some problematic words are euphemism, one-eyed, n-gram. It is possible to write
oper artIndef : Str =
pre {"a" ;
"a" / strs {"eu" ; "one"} ;
"an" / strs {"a" ; "e" ; "i" ; "o" ; "n-"}
} ;
GF has the following predefined categories in abstract syntax:
cat Int ; -- integers, e.g. 0, 5, 743145151019
cat Float ; -- floats, e.g. 0.0, 3.1415926
cat String ; -- strings, e.g. "", "foo", "123"
The objects of each of these categories are literals
as indicated in the comments above. No fun definition
can have a predefined category as its value type, but
they can be used as arguments. For example:
fun StreetAddress : Int -> String -> Address ;
lin StreetAddress number street = {s = number.s ++ street.s} ;
-- e.g. (StreetAddress 10 "Downing Street") : Address
A resource grammar is a grammar built on linguistic grounds, to describe a language rather than a domain. The GF resource grammar library contains resource grammars for 10 languages, is described more closely in the following documents:
However, to give a flavour of both using and writing resource grammars,
we have created a miniature resource, which resides in the
subdirectory resource. Its API consists of the following
modules:
Only these three modules should be opened in applications.
The implementations of the resource are given in the following four modules:
An example use of the resource resides in the
subdirectory applications.
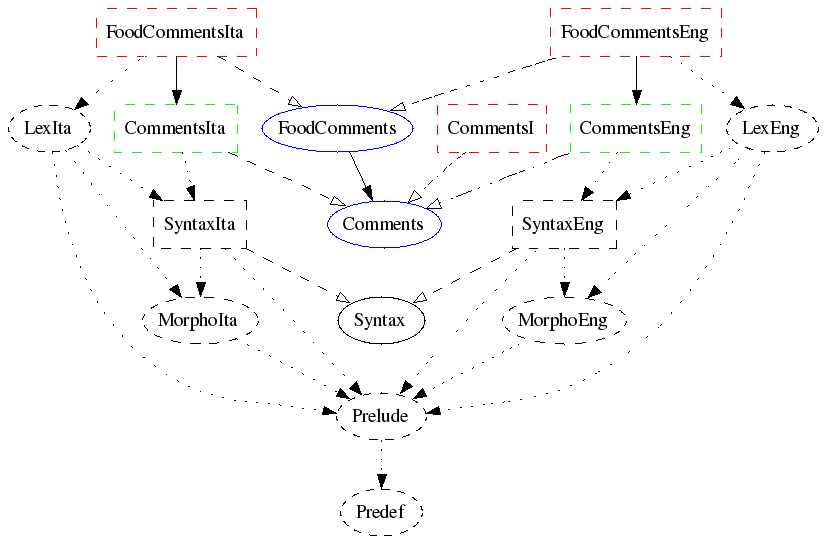
It implements the abstract syntax
FoodComments for English and Italian.
The following diagram shows the module structure, indicating by
colours which modules are written by the grammarian. The two blue modules
form the abstract syntax. The three red modules form the concrete syntax.
The two green modules are trivial instantiations of a functor.
The rest of the modules (black) come from the resource.
Transfer means noncompositional tree-transforming operations.
The command apply_transfer = at is typically used in a pipe:
> p "John walks and John runs" | apply_transfer aggregate | l
John walks and runs
See the sources of this example.
See the transfer language documentation for more information.
Lexers and unlexers can be chosen from
a list of predefined ones, using the flags-lexer and `` -unlexer`` either
in the grammar file or on the GF command line.
Given by help -lexer, help -unlexer:
The default is words.
-lexer=words tokens are separated by spaces or newlines
-lexer=literals like words, but GF integer and string literals recognized
-lexer=vars like words, but "x","x_...","$...$" as vars, "?..." as meta
-lexer=chars each character is a token
-lexer=code use Haskell's lex
-lexer=codevars like code, but treat unknown words as variables, ?? as meta
-lexer=text with conventions on punctuation and capital letters
-lexer=codelit like code, but treat unknown words as string literals
-lexer=textlit like text, but treat unknown words as string literals
-lexer=codeC use a C-like lexer
-lexer=ignore like literals, but ignore unknown words
-lexer=subseqs like ignore, but then try all subsequences from longest
The default is unwords.
-unlexer=unwords space-separated token list (like unwords)
-unlexer=text format as text: punctuation, capitals, paragraph <p>
-unlexer=code format as code (spacing, indentation)
-unlexer=textlit like text, but remove string literal quotes
-unlexer=codelit like code, but remove string literal quotes
-unlexer=concat remove all spaces
-unlexer=bind like identity, but bind at "&+"
Issues:
lincats
optimize flag
-mcfg vs. others
Thespeak_aloud = sa command sends a string to the speech
synthesizer
Flite.
It is typically used via a pipe:
generate_random | linearize | speak_aloud
The result is only satisfactory for English.
The speech_input = si command receives a string from a
speech recognizer that requires the installation of
ATK.
It is typically used to pipe input to a parser:
speech_input -tr | parse
The method words only for grammars of English.
Both Flite and ATK are freely available through the links above, but they are not distributed together with GF.
The Editor User Manual describes the use of the editor, which works for any multilingual GF grammar.
Here is a snapshot of the editor:

The grammars of the snapshot are from the Letter grammar package.
Forthcoming.
Other processes can communicate with the GF command interpreter, and also with the GF syntax editor.
GF grammars can be used as parts of programs written in the following languages. The links give more documentation.
A summary is given in the following chart of GF grammar compiler phases:

Formal and Informal Software Specifications, PhD Thesis by Kristofer Johannisson, is an extensive example of this. The system is based on a multilingual grammar relating the formal language OCL with English and German.
A simpler example will be explained here.