Grammatical Framework Tutorial
3rd Edition, for GF version 2.2 or later
aarne@cs.chalmers.se
12 May 2005
3rd Edition, for GF version 2.2 or later
aarne@cs.chalmers.se
12 May 2005
This tutorial is primarily about the GF program and the GF programming language. It will guide you
There you can download
To start the GF program, assuming you have installed it, just type
gfin the shell. You will see GF's welcome message and the prompt >.
S ::= NP VP ;
VP ::= V | TV NP | "is" A ;
NP ::= ("this" | "that" | "the" | "a") CN ;
CN ::= A CN ;
CN ::= "boy" | "louse" | "snake" | "worm" ;
A ::= "green" | "rotten" | "thick" | "warm" ;
V ::= "laughs" | "sleeps" | "swims" ;
TV ::= "eats" | "kills" | "washes" ;
import paleolithic.gfThe GF program now compiles your grammar into an internal representation, and shows a new prompt when it is ready.
You can use GF for parsing:
> parse "the boy eats a snake" Mks_0 (Mks_6 Mks_9) (Mks_2 Mks_20 (Mks_7 Mks_11)) > parse "the snake eats a boy" Mks_0 (Mks_6 Mks_11) (Mks_2 Mks_20 (Mks_7 Mks_9))The parse (= p) command takes a string (in double quotes) and returns an abstract syntax tree - the thing with Mkss and parentheses. We will see soon how to make sense of the abstract syntax trees - now you should just notice that the tree is different for the two strings.
Strings that return a tree when parsed do so in virtue of the grammar you imported. Try parsing something else, and you fail
> p "hello world" No success in cf parsing no tree found
> linearize Mks_0 (Mks_6 Mks_11) (Mks_2 Mks_20 (Mks_7 Mks_9)) the snake eats a boyWhat is the use of this? Typically not that you type in a tree at the GF prompt. The utility of linearization comes from the fact that you can obtain a tree from somewhere else. One way to do so is random generation (generate_random = gr):
> generate_random Mks_0 (Mks_4 Mks_11) (Mks_3 Mks_15)Now you can copy the tree and paste it to the linearize command. Or, more efficiently, feed random generation into parsing by using a pipe.
> gr | l this worm is warm
> gr -number=10 | l this boy is green a snake laughs the rotten boy is thick a boy washes this worm a boy is warm this green warm boy is rotten the green thick green louse is rotten that boy is green this thick thick boy laughs a boy is green
> generate_trees | l this louse laughs this louse sleeps this louse swims this louse is green this louse is rotten ... a boy is rotten a boy is thick a boy is warmYou get quite a few trees but not all of them: only up to a given depth of trees. To see how you can get more, use the help = h command,
help grQuiz. If the command gt generated all trees in your grammar, it would never terminate. Why?
The intermediate results in a pipe can be observed by putting the tracing flag -tr to each command whose output you want to see:
> gr -tr | l -tr | p Mks_0 (Mks_7 Mks_10) (Mks_1 Mks_18) a louse sleeps Mks_0 (Mks_7 Mks_10) (Mks_1 Mks_18)This facility is good for test purposes: for instance, you may want to see if a grammar is ambiguous, i.e. contains strings that can be parsed in more than one way.
> gr -number=10 | l | write_file exx.tmpYou can read the file back to GF with the read_file = rf command,
> read_file exx.tmp | l -tr | p -linesNotice the flag -lines given to the parsing command. This flag tells GF to parse each line of the file separately. Without the flag, the grammar could not recognize the string in the file, because it is not a sentence but a sequence of ten sentences.
> print_grammar -printer=cf Mks_10. CN ::= "louse" ; Mks_11. CN ::= "snake" ; Mks_12. CN ::= "worm" ; Mks_8. CN ::= A CN ; Mks_9. CN ::= "boy" ; Mks_4. NP ::= "this" CN ; Mks_15. A ::= "thick" ; ...A syntax tree such as
Mks_4 (Mks_8 Mks_15 Mks_12) this thick wormencodes the sequence of grammar rules used for building the expression. If you look at this tree, you will notice that Mks_4 is the label of the rule prefixing this to a common noun, Mks_15 is the label of the adjective thick, and so on.
PredVP. S ::= NP VP ; UseV. VP ::= V ; ComplTV. VP ::= TV NP ; UseA. VP ::= "is" A ; This. NP ::= "this" CN ; That. NP ::= "that" CN ; Def. NP ::= "the" CN ; Indef. NP ::= "a" CN ; ModA. CN ::= A CN ; Boy. CN ::= "boy" ; Louse. CN ::= "louse" ; Snake. CN ::= "snake" ; Worm. CN ::= "worm" ; Green. A ::= "green" ; Rotten. A ::= "rotten" ; Thick. A ::= "thick" ; Warm. A ::= "warm" ; Laugh. V ::= "laughs" ; Sleep. V ::= "sleeps" ; Swim. V ::= "swims" ; Eat. TV ::= "eats" ; Kill. TV ::= "kills" Wash. TV ::= "washes" ;
> empty > i paleolithic.cf > p "the boy eats a snake" PredVP (Def Boy) (ComplTV Eat (Indef Snake)) > gr -tr | l PredVP (Indef Louse) (UseA Thick) a louse is thick
> print_grammarThe output is quite unreadable at this stage, and you may feel happy that you did not need to write the grammar in that notation, but that the GF grammar compiler produced it.
However, we will now start to show how GF's own notation gives you much more expressive power than the .cf and .ebnf formats. We will introduce the .gf format by presenting one more way of defining the same grammar as in paleolithic.cf and paleolithic.ebnf. Then we will show how the full GF grammar format enables you to do things that are not possible in the weaker formats.
PredVP. S ::= NP VP ;is interpreted as the following pair of rules:
fun PredVP : NP -> VP -> S ;
lin PredVP x y = {s = x.s ++ y.s} ;
The former rule, with the keyword fun, belongs to the abstract syntax.
It defines the function
PredVP which constructs syntax trees of form
(PredVP x y).
The latter rule, with the keyword lin, belongs to the concrete syntax. It defines the linearization function for syntax trees of form (PredVP x y).
abstract Paleolithic = {
cat
S ; NP ; VP ; CN ; A ; V ; TV ;
fun
PredVP : NP -> VP -> S ;
UseV : V -> VP ;
ComplTV : TV -> NP -> VP ;
UseA : A -> VP ;
ModA : A -> CN -> CN ;
This, That, Def, Indef : CN -> NP ;
Boy, Louse, Snake, Worm : CN ;
Green, Rotten, Thick, Warm : A ;
Laugh, Sleep, Swim : V ;
Eat, Kill, Wash : TV ;
}
Notice the use of shorthands permitting the sharing of
the keyword in subsequent judgements, and of the type
in subsequent fun judgements.
concrete PaleolithicEng of Paleolithic = {
lincat
S, NP, VP, CN, A, V, TV = {s : Str} ;
lin
PredVP np vp = {s = np.s ++ vp.s} ;
UseV v = v ;
ComplTV tv np = {s = tv.s ++ np.s} ;
UseA a = {s = "is" ++ a.s} ;
This cn = {s = "this" ++ cn.s} ;
That cn = {s = "that" ++ cn.s} ;
Def cn = {s = "the" ++ cn.s} ;
Indef cn = {s = "a" ++ cn.s} ;
ModA a cn = {s = a.s ++ cn.s} ;
Boy = {s = "boy"} ;
Louse = {s = "louse"} ;
Snake = {s = "snake"} ;
Worm = {s = "worm"} ;
Green = {s = "green"} ;
Rotten = {s = "rotten"} ;
Thick = {s = "thick"} ;
Warm = {s = "warm"} ;
Laugh = {s = "laughs"} ;
Sleep = {s = "sleeps"} ;
Swim = {s = "swims"} ;
Eat = {s = "eats"} ;
Kill = {s = "kills"} ;
Wash = {s = "washes"} ;
}
Each module is compiled into a .gfc file.
Import PaleolithicEng.gf and try what happens
> i PaleolithicEng.gfThe GF program does not only read the file PaleolithicEng.gf, but also all other files that it depends on - in this case, Paleolithic.gf.
For each file that is compiles, a .gfc file is generated. The GFC format (="GF Canonical") is the "machine code" of GF, which is faster to process than GF source files. When reading a module, GF knows whether to use an existing .gfc file or to generate a new one, by looking at modification times.
Multilingual grammars can be used for applications such as translation. Let us buid an Italian concrete syntax for Paleolithic and then test the resulting multilingual grammar.
concrete PaleolithicIta of Paleolithic = {
lincat
S, NP, VP, CN, A, V, TV = {s : Str} ;
lin
PredVP np vp = {s = np.s ++ vp.s} ;
UseV v = v ;
ComplTV tv np = {s = tv.s ++ np.s} ;
UseA a = {s = "�" ++ a.s} ;
This cn = {s = "questo" ++ cn.s} ;
That cn = {s = "quello" ++ cn.s} ;
Def cn = {s = "il" ++ cn.s} ;
Indef cn = {s = "un" ++ cn.s} ;
ModA a cn = {s = cn.s ++ a.s} ;
Boy = {s = "ragazzo"} ;
Louse = {s = "pidocchio"} ;
Snake = {s = "serpente"} ;
Worm = {s = "verme"} ;
Green = {s = "verde"} ;
Rotten = {s = "marcio"} ;
Thick = {s = "grosso"} ;
Warm = {s = "caldo"} ;
Laugh = {s = "ride"} ;
Sleep = {s = "dorme"} ;
Swim = {s = "nuota"} ;
Eat = {s = "mangia"} ;
Kill = {s = "uccide"} ;
Wash = {s = "lava"} ;
}
> i PaleolithicEng.gf > i PaleolithicIta.gfTry generation now:
> gr | l un pidocchio uccide questo ragazzo > gr | l -lang=PaleolithicEng that louse eats a louseTranslate by using a pipe:
> p -lang=PaleolithicEng "the boy eats the snake" | l -lang=PaleolithicIta il ragazzo mangia il serpente
To see what the multilingual grammar is (as well as some other things), you can use the command print_options = po:
> print_options main abstract : Paleolithic main concrete : PaleolithicIta all concretes : PaleolithicIta PaleolithicEng
abstract Neolithic = Paleolithic ** {
fun
Fire, Wheel : CN ;
Think : V ;
}
Parallel to the abstract syntax, extensions can
be built for concrete syntaxes:
concrete NeolithicEng of Neolithic = PaleolithicEng ** {
lin
Fire = {s = "fire"} ;
Wheel = {s = "wheel"} ;
Think = {s = "thinks"} ;
}
The effect of extension is that all of the contents of the extended
and extending module are put together.
abstract Fish = {
cat Fish ;
fun Salmon, Perch : Fish ;
}
abstract Mushrooms = {
cat Mushroom ;
fun Cep, Agaric : Mushroom ;
}
They can afterwards be combined in bigger grammars by using
multiple inheritance, i.e. extension of several grammars at the
same time:
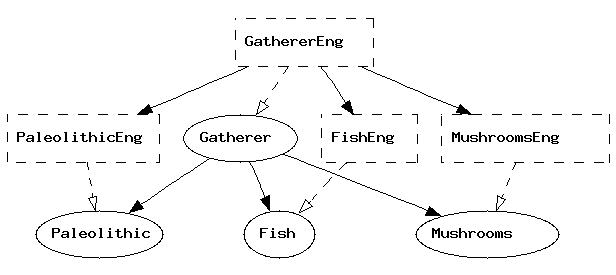
abstract Gatherer = Paleolithic, Fish, Mushrooms ** {
fun
UseFish : Fish -> CN ;
UseMushroom : Mushroom -> CN ;
}
> visualize_graphand the graph will pop up in a separate window. It can also be printed out into a file, e.g. a .gif file that can be included in an HTML document
> pm -printer=graph | wf Gatherer.dot > ! dot -Tgif Gatherer.dot > Gatherer.gifThe latter command is a Unix command, issued from GF by using the shell escape symbol !. The resulting graph is shown in the next section.
The command print_multi = pm is used for printing the current multilingual grammar in various formats, of which the format -printer=graph just shows the module dependencies.
the boy eats two snakes all boys sleepThe new grammatical facility we need are the plural forms of nouns and verbs (boys, sleep), as opposed to their singular forms.
The introduction of plural forms requires two things:
To be able to do all this, we need a couple of new judgement forms, a new module form, and a more powerful way of expressing linearization rules.
param Number = Sg | Pl ;To express that nouns in English have a linearization depending on number, we replace the linearization type {s : Str} with a type where the s field is a table depending on number:
lincat CN = {s : Number => Str} ;
The table type Number => Str is in many respects similar to
a function type (Number -> Str). The main restriction is that the
argument type of a table type must always be a parameter type. This means
that the argument-value pairs can be listed in a finite table. The following
example shows such a table:
lin Boy = {s = table {
Sg => "boy" ;
Pl => "boys"
}
} ;
The application of a table to a parameter is done by the selection
operator !. For instance,
Boy.s ! Plis a selection, whose value is "boys".
From GF point of view, a paradigm is a function that takes a lemma - a string also known as a dictionary form - and returns an inflection table of desired type. Paradigms are not functions in the sense of the fun judgements of abstract syntax (which operate on trees and not on strings). Thus we call them operations for the sake of clarity, introduce one one form of judgement, with the keyword oper. As an example, the following operation defines the regular noun paradigm of English:
oper regNoun : Str -> {s : Number => Str} = \x -> {
s = table {
Sg => x ;
Pl => x + "s"
}
} ;
Thus an oper judgement includes the name of the defined operation,
its type, and an expression defining it. As for the syntax of the defining
expression, notice the lambda abstraction form \x -> t of
the function, and the glueing operator + telling that
the string held in the variable x and the ending "s"
are written together to form one token.
The resource module type thus consists of param and oper definitions. Here is an example.
resource MorphoEng = {
param
Number = Sg | Pl ;
oper
Noun : Type = {s : Number => Str} ;
regNoun : Str -> Noun = \x -> {
s = table {
Sg => x ;
Pl => x + "s"
}
} ;
}
Resource modules can extend other resource modules, in the
same way as modules of other types can extend modules of the
same type.
concrete PaleolithicEng of Paleolithic = open MorphoEng in {
lincat
CN = Noun ;
lin
Boy = regNoun "boy" ;
Snake = regNoun "snake" ;
Worm = regNoun "worm" ;
}
Notice that, just like in abstract syntax, function application
is written by juxtaposition of the function and the argument.
Using operations defined in resource modules is clearly a concise way of giving e.g. inflection tables and other repeated patterns of expression. In addition, it enables a new kind of modularity and division of labour in grammar writing: grammarians familiar with the linguistic details of a language can put this knowledge available through resource grammars, whose users only need to pick the right operations and not to know their implementation details.
oper mkNoun : Str -> Str -> Noun = \x,y -> {
s = table {
Sg => x ;
Pl => y
}
} ;
Thus we define
lin Louse = mkNoun "louse" "lice" ;instead of writing the inflection table explicitly.
The grammar engineering advantage of worst-case macros is that the author of the resource module may change the definitions of Noun and mkNoun, and still retain the interface (i.e. the system of type signatures) that makes it correct to use these functions in concrete modules. In programming terms, Noun is then treated as an abstract datatype.
regNoun : Str -> Noun = \snake -> mkNoun snake (snake + "s") ; sNoun : Str -> Noun = \kiss -> mkNoun kiss (kiss + "es") ;What about nouns like fly, with the plural flies? The already available solution is to use the so-called "technical stem" fl as argument, and define
yNoun : Str -> Noun = \fl -> mkNoun (fl + "y") (fl + "ies") ;But this paradigm would be very unintuitive to use, because the "technical stem" is not even an existing form of the word. A better solution is to use the string operator init, which returns the initial segment (i.e. all characters but the last) of a string:
yNoun : Str -> Noun = \fly -> mkNoun fly (init fly + "ies") ;The operator init belongs to a set of operations in the resource module Prelude, which therefore has to be opened so that init can be used.
Predefined types and operations
Lexers and unlexers
Grammars of formal languages
Resource grammars and their reuse
Embedded grammars in Haskell and Java
Dependent types, variable bindings, semantic definitions
Transfer rules