The GF Resource Grammar Library defines the basic grammar of ten languages: Danish, English, Finnish, French, German, Italian, Norwegian, Russian, Spanish, Swedish.
Notice. This document concerns the API v. 1.0 which has not yet been "officially" released. The release will be made in combination with a new version of GF itself, since the grammars use new features not available in GF 2.4.
V. 1.0 is not yet available for Russian and Danish: for them, we refer to v. 0.9.
Janna Khegai (Russian modules, forthcoming), Bjorn Bringert (many Swadesh lexica), Carlos Gonzalia (Spanish cardinals), Partik Jansson (Swedish cardinals), Aarne Ranta.
We are grateful for contributions and comments to several other people who have used this and the previous versions of the resource library, including David Burke, Lauri Carlson, Gloria Casanellas, Karin Cavallin, Hans-Joachim Daniels, Kristofer Johannisson, Anni Laine, Wanjiku Ng'ang'a, Jordi Saludes.
The GF Resource Grammar Library is open-source software licensed under GNU General Public License. See the file LICENSE for more details.
Coverage, for each language:
Organization:
Presentation:
gfdoc for generating HTML from grammars
This API is accessible by both present and alltenses.
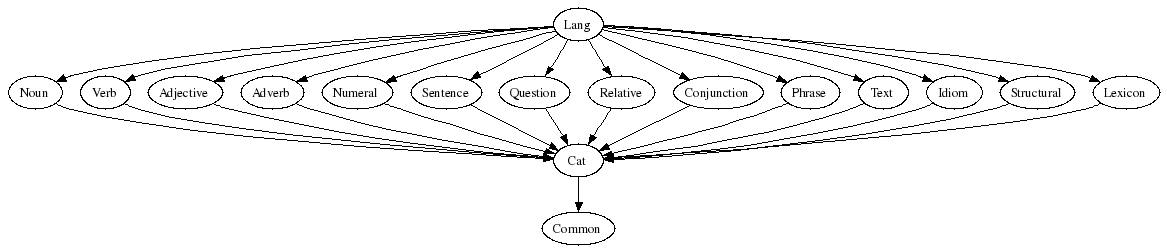
The API is divided into a bunch of abstract modules.
The following figure gives the dependencies of these modules.
The documentation of the individual modules:
The API is the same as for the full ground API, but the compiler
has ignored all verb and sentence tenses except the present.
Lines ignored in the source files are marked by --# notpresent.
The result is a smaller and more efficient grammar, which is still
sufficient for many applications.
The simplest way to get the library is to install the precompiled version
lib/compiled.tgz. Just do
cd GF/lib
tar xvfz compiled.tgz
There is no need to link application grammars to the source directories of the library. Use one (or several) of the following packages instead:
lib/alltenses the complete ground-API library with all forms
lib/present a pruned ground-API library with present tense only
lib/mathematical special-purpose API for mathematical applications
lib/multimodal special-purpose API for multimodal dialogue applications
Notice, however, that both special-purpose APIs share modules with
present. It is therefore not a good idea to use them in combination with
alltenses.
It is advisable to use the bare package names in paths pointing to the
libraries. Here is an example, from examples/tram:
--# -path=.:present:multimodal:mathematical:prelude
To reach these directories from anywhere, set the environment variable
GF_LIB_PATH to point to the directory GF/lib/. For instance,
I have the following line in my .bashrc file:
export GF_LIB_PATH=/home/aarne/GF/lib
If you have done make in lib/resource-1.0, you will have
a file langs.gfcm. This file can be used with fast startup for
tasks such as treebank generation:
> i -nocf langs.gfcm
> gr -cat=S -cf -number=10 | tb
The -nocf flag saves startup time and memory by preventing the
creation of context-free parse grammars.
The resource grammar libraries do not support
parsing very well. While it is theoretically possible to parse with any
GF grammar, the resource grammars are so abstract and complex that
building the actual parser in memory may just need too much resources
to succeed.
An exception is LangEng. It is actually feasible to parse with
both alltenses/LangEng and present/LangEng - the latter being
much faster than the former. The -mcfg flag (multiple context-free grammar)
must be used:
p -lang=LangEng -mcfg "this man is old"
Parsing with the -mcfg flag takes a few extra seconds the first time during
each session, but gets faster at later runs.
These applications are meand to serve as starting points for new applications, showing how the libraries can be used in typical situations.
The examples/bronzeage grammar set implements a language fragment based on the Swadesh list of 200 words. It is useful for things like language training.
The examples/tram grammar set implements the user grammar of a multimodal dialogue system concerning public transport. Its purpose is to serve as a prototype for applications in the TALK project.
The examples/animal grammar set implements some queries about animals. Its purpose is to serve as a prototype for example-based grammar writing.
Grammars as Software Libraries. Slides with background and motivation for the resource grammar library.
How to write resource grammars. Helps you start if you want to add another language to the library.
Parametrized modules for Romance languages. Slides explaining some ideas in the implementation of French, Italian, and Spanish.
Grammar writing by examples. Slides showing how the method is used.
Multimodal Resource Grammars. Slides showing how to use the multimodal resource library.