preliminary version, 17 November 2008
We plan to organize a summer school with the goal of implementing the GF resource grammar library for 15 new languages, so that the library will cover all the 23 official EU languages of year 2009. Also other languages chosen by the participants can be covered. The current library comprises 12 languages.
The library is a linguistic resource that covers the inflectional morphology and basic syntax of each language. It can be used in GF applications and also ported to other formats. The library is licensed under LGPL.
Each language is implemented by one or two students working together. Travel grants will be available for students selected on the basis of pre-conference assignments.
The official announcement will be in January 2009, and the summer school itself on 17-28 August 2009, at the campus of Chalmers University of Technology in Gothenburg, Sweden.
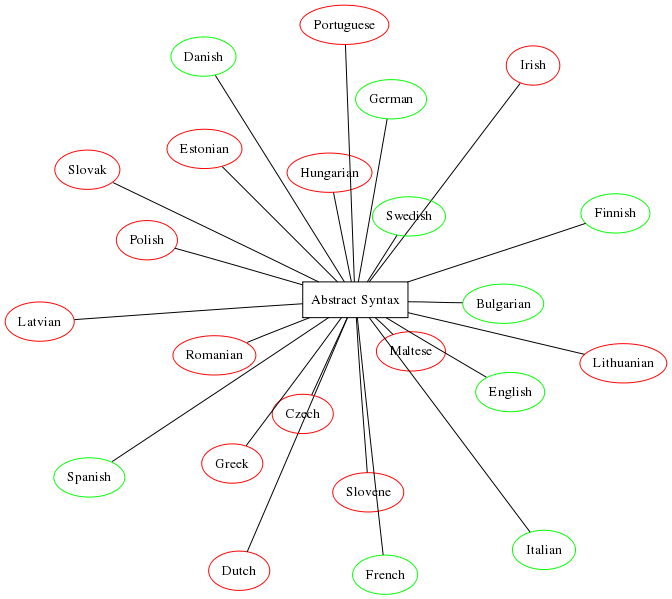
Since 2007, EU-27 has 23 official languages, listed in the diagram on top of this document. There is a growing need of translation between these languages. The traditional language-to-language method requires 23*22 = 506 translators (humans or computer programs) to cover all possible translation needs.
An alternative to language-to-language translation is the use of an interlingua: a language-independent representation such that all translation problems can be reduced to translating to and from the interlingua. With 23 languages, only 2*23 = 46 translators are needed.
Interlingua sounds too good to be true. In a sense, it is. All attempts to create an interlingua that would solve all translation problems have failed. However, interlinguas for restricted applications have shown more success. For instance, mathematical texts and weather reports can be translated by using interlinguas tailor-made for the domains of mathematics and weather reports, respectively.
What is required of an interlingua is
Thus, for instance, an interlingua for mathematical texts may be based on mathematical logic, which at the same time gives semantic accuracy and language independence. In other domains, something else than mathematical logic may be needed; the ontologies defined within the semantic web technology are often good starting points for interlinguas.
The interlingua is just one part of a translation system. We also need the mappings between the interlingua and the involved languages. As the number of languages increases, this part grows while the interlingua remains constant.
GF (Grammatical Framework,
digitalgrammars.com/gf)
is a programming language designed to support interlingua-based translation.
A "program" in GF is a multilingual grammar, which consists of an
abstract syntax and a set of concrete syntaxes. A concrete
syntaxes is a mapping from the abstract syntax to a particular language.
These mappings are reversible, which means that they can be used for
translating in both directions. This means that creating an interlingua-based
translator for 23 languages just requires 1 + 23 = 24 grammar modules (the abstract
syntax and the concrete syntaxes).
The diagram first in this document shows an interlingua system covering the 23 EU languages. Languages marked in red are of particular interest for the summer school, since they are those on which the effort will be concentrated.
The GF resource grammar library is a set of grammars used as libraries when building interlingua-based translation systems. The library currently covers the 9 languages coloured in green in the diagram above; in addition, Catalan, Norwegian, and Russian are covered, and there is ongoing work on Arabic, Hindi/Urdu, and Thai.
The purpose of the resource grammar library is to define the "low-level" structure of a language: inflection, word order, agreement. This structure belongs to what linguists call morphology and syntax. It can be very complex and requires a lot of knowledge. Yet, when translating from one language to another, knowing morphology and syntax is but a part of what is needed. The translator (whether human or machine) must understand the meaning of what is translated, and must also know the idiomatic way to express the meaning in the target language. This knowledge can be very domain-dependent and requires in general an expert in the field to reach high quality: a mathematician in the field of mathematics, a meteorologist in the field of weather reports, etc.
The problem is to find a person who is an expert in both the domain of translation and in the low-level linguistic details. It is the rareness of this combination that has made it difficult to build interlingua-based translation systems. The GF resource grammar library has the mission of helping in this task. It encapsulates the low-level linguistics in program modules accessed through easy-to-use interfaces. Experts on different domains can build translation systems by using the library, without knowing low-level linguistics. The idea is much the same as when a programmer builds a graphical user interface (GUI) from high-level elements such as buttons and menus, without having to care about pixels or geometrical forms.
In addition to translation, the library is also useful in localization, that is, porting a piece of software to new languages. The GF resource grammar library has been used in three major projects that need interlingua-based translation or localization of systems to new languages:
http://www.key-project.org/,
for writing formal and informal software specifications (3 languages)
http://webalt.math.helsinki.fi/content/index_eng.html,
for translating mathematical exercises to 7 languages
http://www.talk-project.org,
where the library was used for localizing spoken dialogue systems to six languages
The library is also a generic linguistic resource, which can be used for tasks such as language teaching and information retrieval. The liberal license (LGPL) makes it usable for anyone and for any task. GF also has tools supporting the use of grammars in programs written in other programming languages: C, C++, Haskell, Java, JavaScript, and Prolog. In connection with the TALK project, support has also been developed for translating GF grammars to language models used in speech recognition (GSL/Nuance, HTK/ATK, SRGS, JSGF).
The library has the following main parts:
The goal of the summer school is to implement, for each language, at least the first three components. The latter three are more open-ended in character.
The goal of the summer school is to extend the GF resource grammar library to covering all 23 EU languages, which means we need 15 new languages. We also welcome other languages, if there are interested participants.
The amount of work and skill is between a Master's thesis and a PhD thesis. The Russian implementation was made by Janna Khegai as a part of her PhD thesis; the thesis contains other material, too. The Arabic implementation was started by Ali El Dada in his Master's thesis, but the thesis does not cover the whole API. The realistic amount of work is somewhere between 3 and 8 person months, but this is very much language-dependent. Dutch, for instance, can profit from previous implementations of German and Scandinavian languages, and will probably require less work. Latvian and Lithuanian are the first languages of the Baltic family and will probably require more work.
In any case, the proposed allocation of work power is 2 participants per language. They will have 6 months to work at home, followed by 2 weeks of summer school. Who are these participants?
After the call has been published, persons interested to participate in the project are expected to learn GF by self-study from the tutorial. This should take a couple of weeks. Also an on-line course will be arranged to help in getting started with GF.
Participants should continue to implement selected parts of the resource grammar, following the advice from the Resource-HOWTO document. What parts exactly are selected will be announced later. This work will take another couple of weeks.
Those who are interested in getting a travel grant will submit their sample resource grammar fragment to the Summer School Committee in the beginning of May. The Committee then decides who is invited to represent which language in the summer school.
After the Committee decision, the participants have around three months to work on their languages. The work is completed in the summer school itself. It is also thoroughly tested by using it to add new languages to applications - in particular, to the WebALT mathematical exercise translator.
Depending on the quality of submitted work, and on the demands of different languages, the Committee may decide to select another number than 2 participants for a language. We will also consider accepting participants who want to pay their own expenses.
To keep track on who is working on which language, we will establish a Wiki page soon after the call is published. The participants are encouraged to contact each other and even work in groups.
Writing a resource grammar implementation requires good general programming skills, and a good explicit knowledge of the grammar of the target language. A typical participant could be
But it is the quality of the assignment that is assessed, not any formal requirements. The "typical participant" was described to give an idea of who is likely to succeed in this.
Our aim is to make the summer school free of charge for the participants who are selected on the basis of their assignments. And not only that: we plan to cover their travel and accommodation costs, up to 1000 EUR per person.
We try to get the funding question settled by mid-February 2009.
A list of teachers will be published here later. Some of the local teachers probably involved are the following:
More teachers are welcome! If you are interested, please contact us so that we can discuss your involvement and travel arrangements.
In addition to teachers, we will look for consultants who can help to assess the results for each language. Please contact us!
This committee consists of a number of teachers and consultants, who will select the participants. It will be selected by February 2009.
The summer school will be organized at the campus of Chalmers University of Technology in Gothenburg, Sweden, on 17-28 August 2009.
Time schedule:
The new resource grammars will be released under the LGPL just like the current resource grammars, with the copyright held by respective authors.
The grammars will be distributed via the GF web site.
The WebALT-specific grammars will have special licenses agreed between the authors and WebALT Inc.
Seven reasons: