mirror of
https://github.com/GrammaticalFramework/gf-core.git
synced 2026-07-08 22:52:46 -06:00
Merge branch 'master' of https://github.com/GrammaticalFramework/GF
This commit is contained in:
@@ -228,6 +228,7 @@ langsCoding = [
|
||||
(("nynorsk", "Nno"),""),
|
||||
(("persian", "Pes"),""),
|
||||
(("polish", "Pol"),""),
|
||||
(("portuguese", "Por"), ""),
|
||||
(("punjabi", "Pnb"),""),
|
||||
(("romanian", "Ron"),""),
|
||||
(("russian", "Rus"),""),
|
||||
@@ -271,7 +272,7 @@ langsPGF = langsLang `except` ["Ara","Hin","Ron","Tha"]
|
||||
-- languages for which Compatibility exists (to be extended)
|
||||
langsCompat = langsLang `only` ["Cat","Eng","Fin","Fre","Ita","Lav","Spa","Swe"]
|
||||
|
||||
gfc bi modes summary files =
|
||||
gfc bi modes summary files =
|
||||
parallel_ [gfcn bi mode summary files | mode<-modes]
|
||||
gfcn bi mode summary files = do
|
||||
let dir = getRGLBuildDir (lbi bi) mode
|
||||
|
||||
@@ -33,7 +33,7 @@ import Network.Shed.Httpd(initServer,Request(..),Response(..),noCache)
|
||||
--import qualified Network.FastCGI as FCGI -- from hackage direct-fastcgi
|
||||
import Network.CGI(handleErrors,liftIO)
|
||||
import CGIUtils(handleCGIErrors)--,outputJSONP,stderrToFile
|
||||
import Text.JSON(encode,showJSON,makeObj)
|
||||
import Text.JSON(JSValue(..),Result(..),valFromObj,encode,decode,showJSON,makeObj)
|
||||
--import System.IO.Silently(hCapture)
|
||||
import System.Process(readProcessWithExitCode)
|
||||
import System.Exit(ExitCode(..))
|
||||
@@ -283,13 +283,17 @@ handle logLn documentroot state0 cache execute1 stateVar
|
||||
skip_empty = filter (not.null.snd)
|
||||
|
||||
jsonList = jsonList' return
|
||||
jsonListLong = jsonList' (mapM addTime)
|
||||
jsonListLong ext = jsonList' (mapM (addTime ext)) ext
|
||||
jsonList' details ext = fmap (json200) (details =<< ls_ext "." ext)
|
||||
|
||||
addTime path =
|
||||
addTime ext path =
|
||||
do t <- getModificationTime path
|
||||
return $ makeObj ["path".=path,"time".=format t]
|
||||
if ext==".json"
|
||||
then addComment (time t) <$> liftIO (try $ getComment path)
|
||||
else return . makeObj $ time t
|
||||
where
|
||||
addComment t = makeObj . either (const t) (\c->t++["comment".=c])
|
||||
time t = ["path".=path,"time".=format t]
|
||||
format = formatTime defaultTimeLocale rfc822DateFormat
|
||||
|
||||
rm path | takeExtension path `elem` ok_to_delete =
|
||||
@@ -331,6 +335,11 @@ handle logLn documentroot state0 cache execute1 stateVar
|
||||
do paths <- getDirectoryContents dir
|
||||
return [path | path<-paths, takeExtension path==ext]
|
||||
|
||||
getComment path =
|
||||
do Ok (JSObject obj) <- decode <$> readFile path
|
||||
Ok cmnt <- return (valFromObj "comment" obj)
|
||||
return (cmnt::String)
|
||||
|
||||
-- * Dynamic content
|
||||
|
||||
jsonresult cwd dir cmd (ecode,stdout,stderr) files =
|
||||
|
||||
@@ -1,13 +1,13 @@
|
||||
name: pgf2
|
||||
version: 0.1.0.0
|
||||
-- synopsis:
|
||||
-- description:
|
||||
-- synopsis:
|
||||
-- description:
|
||||
homepage: http://www.grammaticalframework.org
|
||||
license: LGPL-3
|
||||
--license-file: LICENSE
|
||||
author: Krasimir Angelov, Inari
|
||||
maintainer:
|
||||
-- copyright:
|
||||
maintainer:
|
||||
-- copyright:
|
||||
category: Language
|
||||
build-type: Simple
|
||||
extra-source-files: README
|
||||
@@ -20,13 +20,12 @@ library
|
||||
other-modules: PGF2.FFI, PGF2.Expr, PGF2.Type, SG.FFI
|
||||
build-depends: base >=4.3,
|
||||
containers, pretty
|
||||
-- hs-source-dirs:
|
||||
-- hs-source-dirs:
|
||||
default-language: Haskell2010
|
||||
build-tools: hsc2hs
|
||||
|
||||
extra-libraries: sg pgf gu
|
||||
cc-options: -std=c99
|
||||
default-language: Haskell2010
|
||||
c-sources: utils.c
|
||||
|
||||
executable pgf-shell
|
||||
|
||||
@@ -10,3 +10,22 @@ Executable gfdoc
|
||||
Executable htmls
|
||||
main-is: Htmls.hs
|
||||
build-depends: base
|
||||
|
||||
|
||||
library
|
||||
hs-source-dirs: gftest
|
||||
exposed-modules: Grammar
|
||||
other-modules: Mu, Graph, FMap, EqRel
|
||||
build-depends: base
|
||||
, containers
|
||||
, pgf2
|
||||
|
||||
executable gftest
|
||||
hs-source-dirs: gftest
|
||||
main-is: Main.hs
|
||||
build-depends: base
|
||||
, pgf2
|
||||
, cmdargs
|
||||
, containers
|
||||
, filepath
|
||||
, gf-tools
|
||||
@@ -0,0 +1,32 @@
|
||||
module EqRel where
|
||||
|
||||
import qualified Data.Map as M
|
||||
import Data.List ( sort )
|
||||
|
||||
data EqRel a = Top | Classes [[a]] deriving (Eq,Ord,Show)
|
||||
|
||||
(/\) :: (Ord a) => EqRel a -> EqRel a -> EqRel a
|
||||
Top /\ r = r
|
||||
r /\ Top = r
|
||||
Classes xss /\ Classes yss = Classes $ sort $ map sort $ concat -- maybe throw away singleton lists?
|
||||
[ M.elems tabXs
|
||||
| xs <- xss
|
||||
, let tabXs = M.fromListWith (++)
|
||||
[ (tabYs M.! x, [x])
|
||||
| x <- xs ]
|
||||
]
|
||||
|
||||
where
|
||||
tabYs = M.fromList [ (y,representative)
|
||||
| ys <- yss
|
||||
, let representative = head ys
|
||||
, y <- ys ]
|
||||
|
||||
basic :: (Ord a) => [a] -> EqRel Int
|
||||
basic xs = Classes $ sort $ map sort $ M.elems $ M.fromListWith (++)
|
||||
[ (x,[i]) | (x,i) <- zip xs [0..] ]
|
||||
|
||||
rep :: EqRel Int -> Int -> Int
|
||||
rep Top j = 0
|
||||
rep (Classes xss) j = head [ head xs | xs <- xss, j `elem` xs ]
|
||||
|
||||
@@ -0,0 +1,62 @@
|
||||
module FMap where
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
-- implementation
|
||||
|
||||
data FMap a b = Ask a (FMap a b) (FMap a b) | Nil | Answer b
|
||||
deriving ( Eq, Ord, Show )
|
||||
|
||||
toList :: FMap a b -> [([a],b)]
|
||||
toList t = go [([],t)]
|
||||
where
|
||||
go [] = []
|
||||
go ((xs,Ask x yes no):xts) = go ((x:xs,yes):(xs,no):xts)
|
||||
go ((_ ,Nil) :xts) = go xts
|
||||
go ((xs,Answer z) :xts) = (reverse xs,z) : go xts
|
||||
|
||||
isNil :: FMap a b -> Bool
|
||||
isNil = null . toList
|
||||
|
||||
nil :: FMap a b
|
||||
nil = Nil
|
||||
|
||||
unit :: [a] -> b -> FMap a b
|
||||
unit [] y = Answer y
|
||||
unit (x:xs) y = Ask x (unit xs y) Nil
|
||||
|
||||
covers :: Ord a => FMap a b -> [a] -> Bool
|
||||
Nil `covers` _ = False
|
||||
_ `covers` [] = True
|
||||
Answer _ `covers` _ = False
|
||||
Ask x yes no `covers` zs@(y:ys) =
|
||||
case x `compare` y of
|
||||
LT -> (yes `covers` zs) || (no `covers` zs)
|
||||
EQ -> yes `covers` ys
|
||||
GT -> False
|
||||
|
||||
ask :: a -> FMap a b -> FMap a b -> FMap a b
|
||||
ask x Nil Nil = Nil
|
||||
ask x s t = Ask x s t
|
||||
|
||||
del :: Ord a => [a] -> FMap a b -> FMap a b
|
||||
del _ Nil = Nil
|
||||
del _ (Answer _) = Nil
|
||||
del [] (Ask x yes no) = ask x yes (del [] no)
|
||||
del (x:xs) t@(Ask y yes no) =
|
||||
case x `compare` y of
|
||||
LT -> del xs t
|
||||
EQ -> ask y (del xs yes) (del xs no)
|
||||
GT -> ask y yes (del (x:xs) no)
|
||||
|
||||
add :: Ord a => [a] -> b -> FMap a b -> FMap a b
|
||||
add [] y Nil = Answer y
|
||||
add (x:xs) y Nil = Ask x (add xs y Nil) Nil
|
||||
add xs@(_:_) y (Answer _) = add xs y Nil
|
||||
add (x:xs) y t@(Ask z yes no) =
|
||||
case x `compare` z of
|
||||
LT -> Ask x (add xs y Nil) (del xs t)
|
||||
EQ -> Ask x (add xs y yes) (del xs no)
|
||||
GT -> Ask z yes (add (x:xs) y no)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,193 @@
|
||||
module Graph where
|
||||
|
||||
import qualified Data.Map as M
|
||||
import Data.Map( Map, (!) )
|
||||
import qualified Data.Set as S
|
||||
import Data.Set( Set )
|
||||
import Data.List( nub, sort, (\\) )
|
||||
--import Test.QuickCheck hiding ( generate )
|
||||
|
||||
-- == almost everything in this module is inspired by King & Launchbury ==
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
-- depth-first trees
|
||||
|
||||
data Tree a
|
||||
= Node a [Tree a]
|
||||
| Cut a
|
||||
deriving ( Eq, Show )
|
||||
|
||||
type Forest a
|
||||
= [Tree a]
|
||||
|
||||
top :: Tree a -> a
|
||||
top (Node x _) = x
|
||||
top (Cut x) = x
|
||||
|
||||
-- pruning a possibly infinite forest
|
||||
prune :: Ord a => Forest a -> Forest a
|
||||
prune ts = go S.empty ts
|
||||
where
|
||||
go seen [] = []
|
||||
go seen (Cut x :ts) = Cut x : go seen ts
|
||||
go seen (Node x vs:ts)
|
||||
| x `S.member` seen = Cut x : go seen ts
|
||||
| otherwise = Node x (take n ws) : drop n ws
|
||||
where
|
||||
n = length vs
|
||||
ws = go (S.insert x seen) (vs ++ ts)
|
||||
|
||||
-- pre- and post-order traversals
|
||||
preorder :: Tree a -> [a]
|
||||
preorder t = preorderF [t]
|
||||
|
||||
preorderF :: Forest a -> [a]
|
||||
preorderF ts = go ts []
|
||||
where
|
||||
go [] xs = xs
|
||||
go (Cut x : ts) xs = go ts xs
|
||||
go (Node x vs : ts) xs = x : go vs (go ts xs)
|
||||
|
||||
postorder :: Tree a -> [a]
|
||||
postorder t = postorderF [t]
|
||||
|
||||
postorderF :: Forest a -> [a]
|
||||
postorderF ts = go ts []
|
||||
where
|
||||
go [] xs = xs
|
||||
go (Cut x : ts) xs = go ts xs
|
||||
go (Node x vs : ts) xs = go vs (x : go ts xs)
|
||||
|
||||
-- computing back-arrows
|
||||
backs :: Ord a => Tree a -> Set a
|
||||
backs t = S.fromList (go S.empty t)
|
||||
where
|
||||
go ups (Node x ts) = concatMap (go (S.insert x ups)) ts
|
||||
go ups (Cut x) = [x | x `S.member` ups ]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
-- graphs
|
||||
|
||||
type Graph a
|
||||
= Map a [a]
|
||||
|
||||
vertices :: Graph a -> [a]
|
||||
vertices g = [ x | (x,_) <- M.toList g ]
|
||||
|
||||
transposeG :: Ord a => Graph a -> Graph a
|
||||
transposeG g =
|
||||
M.fromListWith (++) $
|
||||
[ (y,[x]) | (x,ys) <- M.toList g, y <- ys ] ++
|
||||
[ (x,[]) | x <- vertices g ]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
-- graphs and trees
|
||||
|
||||
generate :: Ord a => Graph a -> a -> Tree a
|
||||
generate g x = Node x (map (generate g) (g!x))
|
||||
|
||||
dfs :: Ord a => Graph a -> [a] -> Forest a
|
||||
dfs g xs = prune (map (generate g) xs)
|
||||
|
||||
reach :: Ord a => Graph a -> [a] -> Graph a
|
||||
reach g xs = M.fromList [ (x,g!x) | x <- preorderF (dfs g xs) ]
|
||||
|
||||
dff :: Ord a => Graph a -> Forest a
|
||||
dff g = dfs g (vertices g)
|
||||
|
||||
preOrd :: Ord a => Graph a -> [a]
|
||||
preOrd g = preorderF (dff g)
|
||||
|
||||
postOrd :: Ord a => Graph a -> [a]
|
||||
postOrd g = postorderF (dff g)
|
||||
|
||||
scc1 :: Ord a => Graph a -> Forest a
|
||||
scc1 g = reverse (dfs (transposeG g) (reverse (postOrd g)))
|
||||
|
||||
scc2 :: Ord a => Graph a -> Forest a
|
||||
scc2 g = dfs g (reverse (postOrd (transposeG g)))
|
||||
|
||||
scc :: Ord a => Graph a -> Forest a
|
||||
scc g = scc2 g
|
||||
|
||||
sccs :: Ord a => Graph a -> [[a]]
|
||||
sccs = map preorder . scc
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
-- testing correctness
|
||||
|
||||
{-
|
||||
newtype G = G (Graph Int) deriving ( Show )
|
||||
|
||||
set :: (Ord a, Num a, Arbitrary a) => Gen [a]
|
||||
set = (nub . sort . map abs) `fmap` arbitrary
|
||||
|
||||
instance Arbitrary G where
|
||||
arbitrary =
|
||||
do xs <- set `suchThat` (not . null)
|
||||
yss <- sequence [ listOf (elements xs) | x <- xs ]
|
||||
return (G (M.fromList (xs `zip` yss)))
|
||||
|
||||
shrink (G g) =
|
||||
[ G (delNode x g)
|
||||
| (x,_) <- M.toList g
|
||||
] ++
|
||||
[ G (delEdge x y g)
|
||||
| (x,ys) <- M.toList g
|
||||
, y <- ys
|
||||
]
|
||||
where
|
||||
delNode v g =
|
||||
M.fromList
|
||||
[ (x,filter (v/=) ys)
|
||||
| (x,ys) <- M.toList g
|
||||
, x /= v
|
||||
]
|
||||
|
||||
delEdge v w g =
|
||||
M.insert v ((g!v) \\ [w]) g
|
||||
|
||||
-- all vertices in a component can reach each other
|
||||
prop_Scc_StronglyConnected (G g) =
|
||||
whenFail (print cs) $
|
||||
and [ y `S.member` r | c <- cs, x <- c, let r = reach x, y <- c ]
|
||||
where
|
||||
cs = sccs g
|
||||
|
||||
reach x = go S.empty [x]
|
||||
where
|
||||
go seen [] = seen
|
||||
go seen (x:xs)
|
||||
| x `S.member` seen = go seen xs
|
||||
| otherwise = go (S.insert x seen) ((g!x) ++ xs)
|
||||
|
||||
-- vertices cannot forward-reach to other components
|
||||
prop_Scc_NotConnected (G g) =
|
||||
whenFail (print cs) $
|
||||
-- every vertex is somewhere
|
||||
and [ or [ x `elem` c | c <- cs ]
|
||||
| x <- vertices g
|
||||
] &&
|
||||
-- cannot foward-reach
|
||||
and [ y `S.notMember` rx
|
||||
| (c,d) <- pairs cs
|
||||
, x <- c
|
||||
, let rx = reach x
|
||||
, y <- d
|
||||
]
|
||||
where
|
||||
cs = sccs g
|
||||
|
||||
pairs (x:xs) = [ (x,y) | y <- xs ] ++ pairs xs
|
||||
pairs [] = []
|
||||
|
||||
reach x = go S.empty [x]
|
||||
where
|
||||
go seen [] = seen
|
||||
go seen (x:xs)
|
||||
| x `S.member` seen = go seen xs
|
||||
| otherwise = go (S.insert x seen) ((g!x) ++ xs)
|
||||
-}
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@@ -0,0 +1,401 @@
|
||||
{-# LANGUAGE DeriveDataTypeable #-}
|
||||
|
||||
module Main where
|
||||
|
||||
import Grammar
|
||||
import EqRel
|
||||
|
||||
import Control.Monad ( when )
|
||||
import Data.List ( intercalate, groupBy, sortBy, deleteFirstsBy, isInfixOf )
|
||||
import Data.Maybe ( fromMaybe, mapMaybe )
|
||||
import qualified Data.Set as S
|
||||
import qualified Data.Map as M
|
||||
|
||||
import System.Console.CmdArgs hiding ( name, args )
|
||||
import qualified System.Console.CmdArgs as A
|
||||
import System.FilePath.Posix ( takeFileName )
|
||||
import System.IO ( stdout, hSetBuffering, BufferMode(..) )
|
||||
|
||||
|
||||
data GfTest
|
||||
= GfTest
|
||||
{ grammar :: Maybe FilePath
|
||||
-- Languages
|
||||
, lang :: Lang
|
||||
|
||||
-- Functions and cats
|
||||
, function :: Name
|
||||
, category :: Cat
|
||||
, tree :: String
|
||||
, start_cat :: Maybe Cat
|
||||
, show_cats :: Bool
|
||||
, show_funs :: Bool
|
||||
, show_coercions:: Bool
|
||||
, concr_string :: String
|
||||
|
||||
-- Information about fields
|
||||
, equal_fields :: Bool
|
||||
, empty_fields :: Bool
|
||||
, unused_fields :: Bool
|
||||
, erased_trees :: Bool
|
||||
|
||||
-- Compare to old grammar
|
||||
, old_grammar :: Maybe FilePath
|
||||
, only_changed_cats :: Bool
|
||||
|
||||
-- Misc
|
||||
, treebank :: Maybe FilePath
|
||||
, count_trees :: Maybe Int
|
||||
, debug :: Bool
|
||||
, write_to_file :: Bool
|
||||
|
||||
} deriving (Data,Typeable,Show,Eq)
|
||||
|
||||
gftest = GfTest
|
||||
{ grammar = def &= typFile &= help "Path to the grammar (PGF) you want to test"
|
||||
, lang = def &= A.typ "\"Eng Swe\""
|
||||
&= help "Concrete syntax + optional translations"
|
||||
, tree = def &= A.typ "\"UseN tree_N\""
|
||||
&= A.name "t" &= help "Test the given tree"
|
||||
, function = def &= A.typ "UseN" &= help "Test the given function(s)"
|
||||
, category = def &= A.typ "NP"
|
||||
&= A.name "c" &= help "Test all functions with given goal category"
|
||||
, start_cat = def &= A.typ "Utt"
|
||||
&= A.name "s" &= help "Use the given category as start category"
|
||||
, concr_string = def &= A.typ "the" &= help "Show all functions that include given string"
|
||||
, show_cats = def &= help "Show all available categories"
|
||||
, show_funs = def &= help "Show all available functions"
|
||||
, show_coercions= def &= help "Show coercions in the grammar"
|
||||
, debug = def &= help "Show debug output"
|
||||
, equal_fields = def &= A.name "q" &= help "Show fields whose strings are always identical"
|
||||
, empty_fields = def &= A.name "e" &= help "Show fields whose strings are always empty"
|
||||
, unused_fields = def &= help "Show fields that never make it into the top category"
|
||||
, erased_trees = def &= A.name "r" &= help "Show trees that are erased"
|
||||
, treebank = def &= typFile
|
||||
&= A.name "b" &= help "Path to a treebank"
|
||||
, count_trees = def &= A.typ "3" &= help "Number of trees of size <3>"
|
||||
, old_grammar = def &= typFile
|
||||
&= A.name "o" &= help "Path to an earlier version of the grammar"
|
||||
, only_changed_cats = def &= help "When comparing against an earlier version of a grammar, only test functions in categories that have changed between versions"
|
||||
, write_to_file = def &= help "Write the results in a file (<GRAMMAR>_<FUN>.org)"
|
||||
}
|
||||
|
||||
|
||||
main :: IO ()
|
||||
main = do
|
||||
hSetBuffering stdout NoBuffering
|
||||
|
||||
args <- cmdArgs gftest
|
||||
|
||||
case grammar args of
|
||||
Nothing -> putStrLn "Usage: `gftest -g <PGF grammar> [OPTIONS]'\nTo see available commands, run `gftest --help' or visit https://github.com/GrammaticalFramework/GF/blob/master/src/tools/gftest/README.md"
|
||||
Just fp -> do
|
||||
let (absName,grName) = (takeFileName $ stripPGF fp, stripPGF fp ++ ".pgf") --doesn't matter if the name is given with or without ".pgf"
|
||||
|
||||
(langName:langTrans) = case lang args of
|
||||
[] -> [ absName ++ "Eng" ] -- if no English grammar found, it will be given a default value later
|
||||
langs -> [ absName ++ t | t <- words langs ]
|
||||
|
||||
-- Read grammar and translations
|
||||
gr <- readGrammar langName grName
|
||||
grTrans <- sequence [ readGrammar lt grName | lt <- langTrans ]
|
||||
|
||||
-- in case the language given by the user was not valid, use some language that *is* in the grammar
|
||||
let langName = concrLang gr
|
||||
|
||||
let startcat = startCat gr `fromMaybe` start_cat args
|
||||
|
||||
testTree' t n = testTree False gr grTrans t n ctxs
|
||||
where
|
||||
s = top t
|
||||
c = snd (ctyp s)
|
||||
ctxs = concat [ contextsFor gr sc c
|
||||
| sc <- ccats gr startcat ]
|
||||
|
||||
output = -- Print to stdout or write to a file
|
||||
if write_to_file args
|
||||
then \x ->
|
||||
do let fname = concat [ langName, "_", function args, category args, ".org" ]
|
||||
writeFile fname x
|
||||
putStrLn $ "Wrote results in " ++ fname
|
||||
else putStrLn
|
||||
|
||||
|
||||
intersectConcrCats cats_fields intersection =
|
||||
M.fromListWith intersection
|
||||
([ (c,fields)
|
||||
| (CC (Just c) _,fields) <- cats_fields
|
||||
] ++
|
||||
[ (cat,fields)
|
||||
| (c@(CC Nothing _),fields) <- cats_fields
|
||||
, (CC (Just cat) _,coe) <- coercions gr
|
||||
, c == coe
|
||||
])
|
||||
|
||||
printStats tab =
|
||||
sequence_ [ do putStrLn $ "==> " ++ c ++ ": "
|
||||
putStrLn $ unlines (map (fs!!) xs)
|
||||
| (c,vs) <- M.toList tab
|
||||
, let fs = fieldNames gr c
|
||||
, xs@(_:_) <- [ S.toList vs ] ]
|
||||
-----------------------------------------------------------------------------
|
||||
-- Testing functions
|
||||
|
||||
-- Test a tree
|
||||
case tree args of
|
||||
[] -> return ()
|
||||
t -> output $ testTree' (readTree gr t) 1
|
||||
|
||||
-- Test a function
|
||||
case category args of
|
||||
[] -> return ()
|
||||
cat -> output $ unlines
|
||||
[ testTree' t n
|
||||
| (t,n) <- treesUsingFun gr (functionsByCat gr cat) `zip` [1..]]
|
||||
|
||||
-- Test all functions in a category
|
||||
case function args of
|
||||
[] -> return ()
|
||||
fs -> let funs = if '*' `elem` fs
|
||||
then let subs = filter (/="*") $ groupBy (\a b -> a/='*' && b/='*') fs
|
||||
in nub [ f | s <- symbols gr, let f = show s
|
||||
, all (`isInfixOf` f) subs
|
||||
, arity s >= 1 ]
|
||||
else words fs
|
||||
in output $ unlines
|
||||
[ testFun (debug args) gr grTrans startcat f
|
||||
| f <- funs ]
|
||||
|
||||
-----------------------------------------------------------------------------
|
||||
-- Information about the grammar
|
||||
|
||||
-- Show available categories
|
||||
when (show_cats args) $ do
|
||||
putStrLn "* Categories in the grammar:"
|
||||
putStrLn $ unlines [ cat | (cat,_,_,_) <- concrCats gr ]
|
||||
|
||||
-- Show available functions
|
||||
when (show_funs args) $ do
|
||||
putStrLn "* Functions in the grammar:"
|
||||
putStrLn $ unlines $ nub [ show s | s <- symbols gr ]
|
||||
|
||||
-- Show coercions in the grammar
|
||||
when (show_coercions args) $ do
|
||||
putStrLn "* Coercions in the grammar:"
|
||||
putStrLn $ unlines [ show cat++"--->"++show coe | (cat,coe) <- coercions gr ]
|
||||
|
||||
-- Show all functions that contain the given string
|
||||
-- (e.g. English "it" appears in DefArt, ImpersCl, it_Pron, …)
|
||||
case concr_string args of
|
||||
[] -> return ()
|
||||
str -> do putStrLn $ "### The following functions contain the string '" ++ str ++ "':"
|
||||
putStr "==> "
|
||||
putStrLn $ intercalate ", " $ nub [ name s | s <- hasConcrString gr str]
|
||||
|
||||
-- Show empty fields
|
||||
when (empty_fields args) $ do
|
||||
putStrLn "### Empty fields:"
|
||||
printStats $ intersectConcrCats (emptyFields gr) S.intersection
|
||||
putStrLn ""
|
||||
|
||||
-- Show erased trees
|
||||
when (erased_trees args) $ do
|
||||
putStrLn "* Erased trees:"
|
||||
sequence_
|
||||
[ do putStrLn ("** " ++ intercalate "," erasedTrees ++ " : " ++ uncoerceAbsCat gr c)
|
||||
sequence_
|
||||
[ do putStrLn ("- Tree: " ++ showTree t)
|
||||
putStrLn ("- Lin: " ++ s)
|
||||
putStrLn $ unlines
|
||||
[ "- Trans: "++linearize tgr t
|
||||
| tgr <- grTrans ]
|
||||
| t <- ts
|
||||
, let s = linearize gr t
|
||||
, let erasedSymbs = [ sym | sym <- flatten t, c==snd (ctyp sym) ]
|
||||
]
|
||||
| top <- take 1 $ ccats gr startcat
|
||||
, (c,ts) <- forgets gr top
|
||||
, let erasedTrees =
|
||||
concat [ [ showTree subtree
|
||||
| sym <- flatten t
|
||||
, let csym = snd (ctyp sym)
|
||||
, c == csym || coerces gr c csym
|
||||
, let Just subtree = subTree sym t ]
|
||||
| t <- ts ]
|
||||
]
|
||||
putStrLn ""
|
||||
|
||||
-- Show unused fields
|
||||
when (unused_fields args) $ do
|
||||
|
||||
let unused =
|
||||
[ (c,S.fromList notUsed)
|
||||
| tp <- ccats gr startcat
|
||||
, (c,is) <- reachableFieldsFromTop gr tp
|
||||
, let ar = head $
|
||||
[ length (seqs f)
|
||||
| f <- symbols gr, snd (ctyp f) == c ] ++
|
||||
[ length (seqs f)
|
||||
| (b,a) <- coercions gr, a == c
|
||||
, f <- symbols gr, snd (ctyp f) == b ]
|
||||
notUsed = [ i | i <- [0..ar-1], i `notElem` is ]
|
||||
, not (null notUsed)
|
||||
]
|
||||
putStrLn "### Unused fields:"
|
||||
printStats $ intersectConcrCats unused S.intersection
|
||||
putStrLn ""
|
||||
|
||||
-- Show equal fields
|
||||
let tab = intersectConcrCats (equalFields gr) (/\)
|
||||
when (equal_fields args) $ do
|
||||
putStrLn "### Equal fields:"
|
||||
sequence_
|
||||
[ putStrLn ("==> " ++ c ++ ":\n" ++ cl)
|
||||
| (c,eqr) <- M.toList tab
|
||||
, let fs = fieldNames gr c
|
||||
, cl <- case eqr of
|
||||
Top -> ["TOP"]
|
||||
Classes xss -> [ unlines (map (fs!!) xs)
|
||||
| xs@(_:_:_) <- xss ]
|
||||
]
|
||||
putStrLn ""
|
||||
|
||||
case count_trees args of
|
||||
Nothing -> return ()
|
||||
Just n -> do let start = head $ ccats gr startcat
|
||||
let i = featCard gr start n
|
||||
let iTot = sum [ featCard gr start m | m <- [1..n] ]
|
||||
putStr $ "There are "++show iTot++" trees up to size "++show n
|
||||
putStrLn $ ", and "++show i++" of exactly size "++show n++".\nFor example: "
|
||||
putStrLn $ "* " ++ show (featIth gr start n 0)
|
||||
putStrLn $ "* " ++ show (featIth gr start n (i-1))
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
-- Comparison with old grammar
|
||||
|
||||
case old_grammar args of
|
||||
Nothing -> return ()
|
||||
Just fp -> do
|
||||
oldgr <- readGrammar langName (stripPGF fp ++ ".pgf")
|
||||
let ogr = oldgr { concrLang = concrLang oldgr ++ "-OLD" }
|
||||
difcats = diffCats ogr gr -- (acat, [#o, #n], olabels, nlabels)
|
||||
|
||||
--------------------------------------------------------------------------
|
||||
-- generate statistics of the changes in the concrete categories
|
||||
let ccatChangeFile = langName ++ "-ccat-diff.org"
|
||||
writeFile ccatChangeFile ""
|
||||
sequence_
|
||||
[ appendFile ccatChangeFile $ unlines
|
||||
[ "* " ++ acat
|
||||
, show o ++ " concrete categories in the old grammar,"
|
||||
, show n ++ " concrete categories in the new grammar."
|
||||
, "** Labels only in old (" ++ show (length ol) ++ "):"
|
||||
, intercalate ", " ol
|
||||
, "** Labels only in new (" ++ show (length nl) ++ "):"
|
||||
, intercalate ", " nl ]
|
||||
| (acat, [o,n], ol, nl) <- difcats ]
|
||||
when (debug args) $
|
||||
sequence_
|
||||
[ appendFile ccatChangeFile $
|
||||
unlines $
|
||||
("* All concrete cats in the "++age++" grammar:"):
|
||||
[ show cats | cats <- concrCats g ]
|
||||
| (g,age) <- [(ogr,"old"),(gr,"new")] ]
|
||||
|
||||
putStrLn $ "Created file " ++ ccatChangeFile
|
||||
|
||||
--------------------------------------------------------------------------
|
||||
-- print out tests for all functions in the changed cats
|
||||
|
||||
let changedFuns =
|
||||
if only_changed_cats args
|
||||
then [ (cat,functionsByCat gr cat) | (cat,_,_,_) <- difcats ]
|
||||
else
|
||||
case category args of
|
||||
[] -> case function args of
|
||||
[] -> [ (cat,functionsByCat gr cat)
|
||||
| (cat,_,_,_) <- concrCats gr ]
|
||||
fn -> [ (snd $ Grammar.typ f, [f])
|
||||
| f <- lookupSymbol gr fn ]
|
||||
ct -> [ (ct,functionsByCat gr ct) ]
|
||||
writeLinFile file grammar otherGrammar = do
|
||||
writeFile file ""
|
||||
putStrLn "Testing functions in… "
|
||||
diff <- concat `fmap`
|
||||
sequence [ do let cs = [ compareTree grammar otherGrammar grTrans t
|
||||
| t <- treesUsingFun grammar funs ]
|
||||
putStr $ cat ++ " \r"
|
||||
-- prevent lazy evaluation; make printout accurate
|
||||
appendFile ("/tmp/"++file) (unwords $ map show cs)
|
||||
return cs
|
||||
| (cat,funs) <- changedFuns ]
|
||||
let relevantDiff = go [] [] diff where
|
||||
go res seen [] = res
|
||||
go res seen (Comparison f ls:cs) =
|
||||
if null uniqLs then go res seen cs
|
||||
else go (Comparison f uniqLs:res) (uniqLs++seen) cs
|
||||
where uniqLs = deleteFirstsBy ctxEq ls seen
|
||||
ctxEq (a,_,_,_) (b,_,_,_) = a==b
|
||||
shorterTree c1 c2 = length (funTree c1) `compare` length (funTree c2)
|
||||
writeFile file $ unlines
|
||||
[ show comp
|
||||
| comp <- sortBy shorterTree relevantDiff ]
|
||||
|
||||
|
||||
writeLinFile (langName ++ "-lin-diff.org") gr ogr
|
||||
putStrLn $ "Created file " ++ (langName ++ "-lin-diff.org")
|
||||
|
||||
---------------------------------------------------------------------------
|
||||
-- Print statistics about the functions: e.g., in the old grammar,
|
||||
-- all these 5 functions used to be in the same category:
|
||||
-- [DefArt,PossPron,no_Quant,this_Quant,that_Quant]
|
||||
-- but in the new grammar, they are split into two:
|
||||
-- [DefArt,PossPron,no_Quant] and [this_Quant,that_Quant].
|
||||
let groupFuns grammar = -- :: Grammar -> [[Symbol]]
|
||||
concat [ groupBy sameCCat $ sortBy compareCCat funs
|
||||
| (cat,_,_,_) <- difcats
|
||||
, let funs = functionsByCat grammar cat ]
|
||||
|
||||
sortByName = sortBy (\s t -> name s `compare` name t)
|
||||
writeFunFile groupedFuns file grammar = do
|
||||
writeFile file ""
|
||||
sequence_ [ do appendFile file "---\n"
|
||||
appendFile file $ unlines
|
||||
[ showConcrFun gr fun
|
||||
| fun <- sortByName funs ]
|
||||
| funs <- groupedFuns ]
|
||||
|
||||
writeFunFile (groupFuns ogr) (langName ++ "-old-funs.org") ogr
|
||||
writeFunFile (groupFuns gr) (langName ++ "-new-funs.org") gr
|
||||
|
||||
putStrLn $ "Created files " ++ langName ++ "-(old|new)-funs.org"
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
-- Read trees from treebank. No fancier functionality yet.
|
||||
|
||||
case treebank args of
|
||||
Nothing -> return ()
|
||||
Just fp -> do
|
||||
tb <- readFile fp
|
||||
sequence_ [ do let tree = readTree gr str
|
||||
ccat = ccatOf tree
|
||||
putStrLn $ unlines [ "", showTree tree ++ " : " ++ show ccat]
|
||||
putStrLn $ linearize gr tree
|
||||
| str <- lines tb ]
|
||||
|
||||
|
||||
where
|
||||
|
||||
nub = S.toList . S.fromList
|
||||
|
||||
sameCCat :: Symbol -> Symbol -> Bool
|
||||
sameCCat s1 s2 = snd (ctyp s1) == snd (ctyp s2)
|
||||
|
||||
compareCCat :: Symbol -> Symbol -> Ordering
|
||||
compareCCat s1 s2 = snd (ctyp s1) `compare` snd (ctyp s2)
|
||||
|
||||
stripPGF :: String -> String
|
||||
stripPGF s = case reverse s of
|
||||
'f':'g':'p':'.':name -> reverse name
|
||||
name -> s
|
||||
|
||||
@@ -0,0 +1,113 @@
|
||||
module Mu where
|
||||
|
||||
import Data.Map( Map, (!) )
|
||||
import qualified Data.Map as M
|
||||
import Data.Set( Set )
|
||||
import qualified Data.Set as S
|
||||
import Graph
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
-- naive implementation of fixpoint computation
|
||||
mu0 :: (Ord x, Eq a) => a -> [(x, [x], [a] -> a)] -> [x] -> [a]
|
||||
mu0 bot defs zs = [ done!z | z <- zs ]
|
||||
where
|
||||
xs = [ x | (x, _, _) <- defs ]
|
||||
done = iter [ bot | _ <- xs ]
|
||||
|
||||
iter as
|
||||
| as == as' = tab
|
||||
| otherwise = iter as'
|
||||
where
|
||||
tab = M.fromList (xs `zip` as)
|
||||
as' = [ f [ tab!y | y <- ys ]
|
||||
| (_,(_, ys, f)) <- as `zip` defs
|
||||
]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
-- scc-based implementation of fixpoint computation
|
||||
{-
|
||||
a --^ initial/bottom value (smallest element) in the fixpoint computation
|
||||
-> [( x, [x] --^ A single category, its arguments
|
||||
, [a] -> a) --^ function that takes as its argument a list of values that we want to compute for the [x]
|
||||
]
|
||||
-> [x] --^ All categories that you want to see the answer for
|
||||
-> [a] --^ Values for the given categories
|
||||
-}
|
||||
|
||||
mu :: (Ord x, Eq a) => a -> [(x, [x], [a] -> a)] -> [x] -> [a]
|
||||
mu bot defs zs = [ vtab?z | z <- zs ]
|
||||
where
|
||||
ftab = M.fromList [ (x,f) | (x,_,f) <- defs ]
|
||||
graph = reach (M.fromList [ (x,xs) | (x,xs,_) <- defs ]) zs
|
||||
vtab = foldl compute M.empty (scc graph)
|
||||
|
||||
compute vtab t = fix (-1) vtab (map (vtab ?) xs)
|
||||
where
|
||||
xs = S.toList (backs t)
|
||||
|
||||
fix 0 vtab _ = vtab
|
||||
fix n vtab as
|
||||
| as' == as = vtab'
|
||||
| otherwise = fix (n-1) vtab' as'
|
||||
where
|
||||
(_,vtab') = eval t vtab
|
||||
as' = map (vtab' ?) xs
|
||||
|
||||
eval (Cut x) vtab = (vtab?x, vtab)
|
||||
eval (Node x ts) vtab = (a, M.insert x a vtab')
|
||||
where
|
||||
(as, vtab') = evalList ts vtab
|
||||
a = (ftab!x) as
|
||||
|
||||
evalList [] vtab = ([], vtab)
|
||||
evalList (t:ts) vtab = (a:as, vtab'')
|
||||
where
|
||||
(a, vtab') = eval t vtab
|
||||
(as,vtab'') = evalList ts vtab'
|
||||
|
||||
vtab ? x = case M.lookup x vtab of
|
||||
Nothing -> bot
|
||||
Just a -> a
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
-- diff/scc-based implementation of fixpoint computation
|
||||
muDiff :: (Ord x, Eq a)
|
||||
=> a -> (a->Bool) -> (a->a->a) -> (a->a->a)
|
||||
-> [(x, [x], [a] -> a)]
|
||||
-> [x] -> [a]
|
||||
muDiff bot isBot diff apply defs zs = [ vtab?z | z <- zs ]
|
||||
where
|
||||
ftab = M.fromList [ (x,f) | (x,_,f) <- defs ]
|
||||
graph = reach (M.fromList [ (x,xs) | (x,xs,_) <- defs ]) zs
|
||||
vtab = foldl compute M.empty (scc graph)
|
||||
|
||||
compute vtab t = fix vtab M.empty
|
||||
where
|
||||
xs = S.toList (backs t)
|
||||
|
||||
fix dtab vtab
|
||||
| all isBot ds = vtab'
|
||||
| otherwise = fix (M.fromList (xs `zip` ds)) vtab'
|
||||
where
|
||||
dtab' = eval t dtab
|
||||
vtab' = foldr (\(x,d) -> M.alter (Just . apply' d) x) vtab (M.toList dtab')
|
||||
ds = map (dtab' ?) xs
|
||||
|
||||
apply' d Nothing = apply d bot
|
||||
apply' d (Just a) = apply d a
|
||||
|
||||
eval (Cut x) tab = tab
|
||||
eval (Node x ts) tab = M.insert x d tab'
|
||||
where
|
||||
tab' = foldl (flip eval) tab ts
|
||||
d = (ftab!x) [ tab'?x | x <- map top ts ] `diff` (vtab?x)
|
||||
|
||||
vtab ? x = case M.lookup x vtab of
|
||||
Nothing -> bot
|
||||
Just a -> a
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@@ -0,0 +1,430 @@
|
||||
# gftest: Automatic systematic test case generation for GF grammars
|
||||
|
||||
`gftest` is a program for automatically generating systematic test
|
||||
cases for GF grammars. The basic use case is to give `gftest` a
|
||||
PGF grammar, a concrete language and a function; then `gftest` generates a
|
||||
representative and minimal set of example sentences for a human to look at.
|
||||
|
||||
There are examples of actual generated test cases later in this
|
||||
document, as well as the full list of options to give to `gftest`.
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [Installation](#installation)
|
||||
- [Prerequisites](#prerequisites)
|
||||
- [Install gftest](#install-gftest)
|
||||
- [Common use cases](#common-use-cases)
|
||||
- [Grammar: `-g`](#grammar--g)
|
||||
- [Language: `-l`](#language--l)
|
||||
- [Function(s) to test: `-f`](#functions-to-test--f)
|
||||
- [Start category for context: `-s`](#start-category-for-context--s)
|
||||
- [Category to test: `-c`](#category-to-test--c)
|
||||
- [Tree to test: `-t`](#tree-to-test--t)
|
||||
- [Compare against an old version of the grammar: `-o`](#compare-against-an-old-version-of-the-grammar--o)
|
||||
- [Information about a particular string: `--concr-string`](#information-about-a-particular-string---concr-string)
|
||||
- [Write into a file: `-w`](#write-into-a-file--w)
|
||||
- [Less common use cases](#less-common-use-cases)
|
||||
- [Empty or always identical fields: `-e`, `-q`](#empty-or-always-identical-fields--e--q)
|
||||
- [Unused fields: `-u`](#unused-fields--u)
|
||||
- [Erased trees: `-r`](#erased-trees--r)
|
||||
- [--show-coercions](#--show-coercions)
|
||||
- [--count-trees](#--count-trees)
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
### Prerequisites
|
||||
|
||||
You need the library `PGF2`. Here are instructions how to install:
|
||||
|
||||
1) Install C runtime: go to the directory [GF/src/runtime/c](https://github.com/GrammaticalFramework/GF/tree/master/src/runtime/c), see
|
||||
instructions in INSTALL
|
||||
1) Install PGF2 in one of the two ways:
|
||||
* **EITHER** Go to the directory
|
||||
[GF/src/runtime/haskell-bind](https://github.com/GrammaticalFramework/GF/tree/master/src/runtime/haskell-bind),
|
||||
do `cabal install`
|
||||
* **OR** Go to the root directory of
|
||||
[GF](https://github.com/GrammaticalFramework/GF/) and compile GF
|
||||
with C-runtime system support: `cabal
|
||||
install -fc-runtime`, see more information [here](http://www.grammaticalframework.org/doc/gf-developers.html#toc16).
|
||||
|
||||
### Install gftest
|
||||
|
||||
Go to
|
||||
[GF/src/tools](https://github.com/GrammaticalFramework/GF/tree/master/src/tools),
|
||||
do `cabal install`. It creates an executable `gftest`.
|
||||
|
||||
|
||||
## Common use cases
|
||||
|
||||
Run `gftest --help` of `gftest -?` to get the list of options.
|
||||
|
||||
```
|
||||
Common flags:
|
||||
-g --grammar=FILE Path to the grammar (PGF) you want to test
|
||||
-l --lang="Eng Swe" Concrete syntax + optional translations
|
||||
-f --function=UseN Test the given function(s)
|
||||
-c --category=NP Test all functions with given goal category
|
||||
-t --tree="UseN tree_N" Test the given tree
|
||||
-s --start-cat=Utt Use the given category as start category
|
||||
--show-cats Show all available categories
|
||||
--show-funs Show all available functions
|
||||
--show-coercions Show coercions in the grammar
|
||||
--concr-string=the Show all functions that include given string
|
||||
-q --equal-fields Show fields whose strings are always identical
|
||||
-e --empty-fields Show fields whose strings are always empty
|
||||
-u --unused-fields Show fields that never make it into the top category
|
||||
-r --erased-trees Show trees that are erased
|
||||
-o --old-grammar=ITEM Path to an earlier version of the grammar
|
||||
--only-changed-cats When comparing against an earlier version of a
|
||||
grammar, only test functions in categories that have
|
||||
changed between versions
|
||||
-b --treebank=ITEM Path to a treebank
|
||||
--count-trees=3 Number of trees of depth <depth>
|
||||
-d --debug Show debug output
|
||||
-w --write-to-file Write the results in a file (<GRAMMAR>_<FUN>.org)
|
||||
-? --help Display help message
|
||||
-V --version Print version information
|
||||
```
|
||||
|
||||
### Grammar: `-g`
|
||||
|
||||
Give the PGF grammar as an argument with `-g`. If the file is not in
|
||||
the same directory, you need to give the full file path.
|
||||
|
||||
You can give the grammar with or without `.pgf`.
|
||||
|
||||
Without a concrete syntax you can't do much, but you can see the
|
||||
available categories and functions with `--show-cats` and `--show-funs`
|
||||
|
||||
Examples:
|
||||
|
||||
* `gftest -g Foods --show-funs`
|
||||
* `gftest -g /home/inari/grammars/LangEng.pgf --show-cats`
|
||||
|
||||
|
||||
### Language: `-l`
|
||||
|
||||
Give a concrete language. It assumes the format `AbsNameConcName`, and you should only give the `ConcName` part.
|
||||
|
||||
You can give multiple languages, in which case it will create the test cases based on the first, and show translations in the rest.
|
||||
|
||||
Examples:
|
||||
|
||||
* `gftest -g Phrasebook -l Swe --show-cats`
|
||||
* `gftest -g Foods -l "Spa Eng" -f Pizza`
|
||||
|
||||
### Function(s) to test: `-f`
|
||||
|
||||
Given a grammar (`-g`) and a concrete language ( `-l`), test a function or several functions.
|
||||
|
||||
Examples:
|
||||
|
||||
* `gftest -g Lang -l "Dut Eng" -f UseN`
|
||||
* `gftest -g Phrasebook -l Spa -f "ByTransp ByFoot"`
|
||||
|
||||
You can use the wildcard `*`, if you want to match multiple functions. Examples:
|
||||
|
||||
* `gftest -g Lang -l Eng -f "*hat*"`
|
||||
|
||||
matches `hat_N, hate_V2, that_Quant, that_Subj, whatPl_IP` and `whatSg_IP`.
|
||||
|
||||
* `gftest -g Lang -l Eng -f "*hat*u*"`
|
||||
|
||||
matches `that_Quant` and `that_Subj`.
|
||||
|
||||
* `gftest -g Lang -l Eng -f "*"`
|
||||
|
||||
matches all functions in the grammar. (As of March 2018, takes 13
|
||||
minutes for the English resource grammar, and results in ~40k
|
||||
lines. You may not want to do this for big grammars.)
|
||||
|
||||
### Start category for context: `-s`
|
||||
|
||||
Give a start category for contexts. Used in conjunction with `-f`,
|
||||
`-c`, `-t` or `--count-trees`. If not specified, contexts are created
|
||||
for the start category of the grammar.
|
||||
|
||||
Example:
|
||||
|
||||
* `gftest -g Lang -l "Dut Eng" -f UseN -s Adv`
|
||||
|
||||
This creates a hole of `CN` in `Adv`, instead of the default start category.
|
||||
|
||||
### Category to test: `-c`
|
||||
|
||||
Given a grammar (`-g`) and a concrete language ( `-l`), test all functions that return a given category.
|
||||
|
||||
Examples:
|
||||
|
||||
* `gftest -g Phrasebook -l Fre -c Modality`
|
||||
* `gftest -g Phrasebook -l Fre -c ByTransport -s Action`
|
||||
|
||||
|
||||
### Tree to test: `-t`
|
||||
|
||||
Given a grammar (`-g`) and a concrete language ( `-l`), test a complete tree.
|
||||
|
||||
Example:
|
||||
|
||||
* `gftest -g Phrasebook -l Dut -t "ByTransp Bus"`
|
||||
|
||||
You can combine it with any of the other flags, e.g. put it in a
|
||||
different start category:
|
||||
|
||||
* `gftest -g Phrasebook -l Dut -t "ByTransp Bus" -s Action`
|
||||
|
||||
|
||||
This may be useful for the following case. Say you tested `PrepNP`,
|
||||
and the default NP it gave you only uses the word *car*, but you
|
||||
would really want to see it for some other noun—maybe `car_N` itself
|
||||
is buggy, and you want to be sure that `PrepNP` works properly. So
|
||||
then you can call the following:
|
||||
|
||||
* `gftest -g TestLang -l Eng -t "PrepNP with_Prep (MassNP (UseN beer_N))"`
|
||||
|
||||
### Compare against an old version of the grammar: `-o`
|
||||
|
||||
Give a grammar, a concrete syntax, and an old version of the same
|
||||
grammar as a separate PGF file. The program generates test sentences
|
||||
for all functions, linearises with both grammars, and outputs those
|
||||
that differ between the versions. It writes the differences into files.
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
> gftest -g TestLang -l Eng -o TestLangOld
|
||||
Created file TestLangEng-ccat-diff.org
|
||||
Testing functions in…
|
||||
<categories flashing by>
|
||||
Created file TestLangEng-lin-diff.org
|
||||
Created files TestLangEng-(old|new)-funs.org
|
||||
```
|
||||
|
||||
* TestLangEng-ccat-diff.org: All concrete categories that have
|
||||
changed. Shows e.g. if you added or removed a parameter or a
|
||||
field.
|
||||
|
||||
* TestLangEng-lin-diff.org: All trees that have different
|
||||
linearisations in the following format. **This is usually the most
|
||||
relevant file.**
|
||||
```
|
||||
* send_V3
|
||||
|
||||
** UseCl (TTAnt TPres ASimul) PPos (PredVP (UsePron we_Pron) (ReflVP (Slash3V3 ∅ (UsePron it_Pron))))
|
||||
TestLangDut> we sturen onszelf ernaar
|
||||
TestLangDut-OLD> we sturen zichzelf ernaar
|
||||
|
||||
|
||||
** UseCl (TTAnt TPast ASimul) PPos (PredVP (UsePron we_Pron) (ReflVP (Slash3V3 ∅ (UsePron it_Pron))))
|
||||
TestLangDut> we stuurden onszelf ernaar
|
||||
TestLangDut-OLD> we stuurden zichzelf ernaar
|
||||
```
|
||||
|
||||
* TestLangEng-old-funs.org and TestLangEng-new-funs.org: groups the
|
||||
functions by their concrete categories. Shows difference if you have
|
||||
e.g. added or removed parameters, and that has created new versions of
|
||||
some functions: say you didn't have gender in nouns, but now you
|
||||
have, then all functions taking nouns have suddenly a gendered
|
||||
version. **This is kind of hard to read, don't worry too much if the
|
||||
output doesn't make any sense.**
|
||||
|
||||
You can give an additional parameter, `--only-changed-cats`, if you
|
||||
only want to test functions in those categories that you have changed,
|
||||
like this: `gftest -g TestLang -l Eng -o TestLangOld
|
||||
--only-changed-cats`. This makes it run faster.
|
||||
|
||||
### Information about a particular string: `--concr-string`
|
||||
|
||||
Show all functions where the given concrete string appears as syncategorematic string (i.e. not from the arguments).
|
||||
|
||||
Example:
|
||||
|
||||
* `gftest -l Eng --concr-string it`
|
||||
|
||||
which gives the answer `==> CleftAdv, CleftNP, DefArt, ImpersCl, it_Pron`
|
||||
|
||||
|
||||
### Write into a file: `-w`
|
||||
|
||||
Writes the results into a file of format `<GRAMMAR>_<FUN or CAT>.org`,
|
||||
e.g. TestLangEng-UseN.org. Recommended to open it in emacs org-mode,
|
||||
so you get an overview, and you can maybe ignore some trees if you
|
||||
think they are redundant.
|
||||
|
||||
1) When you open the file, you see a list of generated test cases, like this: 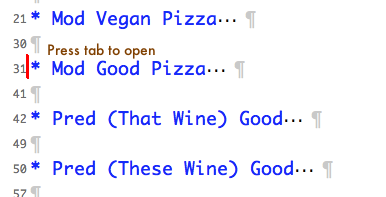
|
||||
Place cursor to the left and click tab to open it.
|
||||
|
||||
2) You get a list of contexts for the test case. Keep the cursor where it was if you want to open everything at the same time. Alternatively, scroll down to one of the contexts and press tab there, if you only want to open one.
|
||||
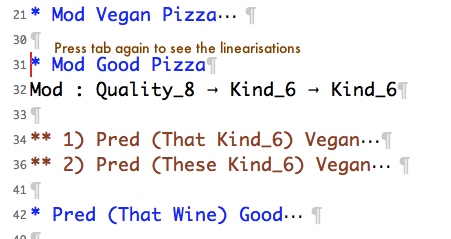
|
||||
|
||||
3) Now you can read the linearisations.
|
||||
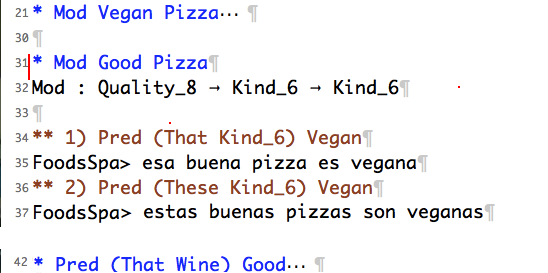
|
||||
|
||||
If you want to close the test case, just press tab again, keeping the
|
||||
cursor where it's been all the time (line 31 in the pictures).
|
||||
|
||||
## Less common use cases
|
||||
|
||||
The topics here require some more obscure GF-fu. No need to worry if
|
||||
the terms are not familiar to you.
|
||||
|
||||
|
||||
### Empty or always identical fields: `-e`, `-q`
|
||||
|
||||
Information about the fields: always empty, or always equal to each
|
||||
other. Example of empty fields:
|
||||
|
||||
```
|
||||
> gftest -g Lang -l Dut -e
|
||||
* Empty fields:
|
||||
==> Ant: s
|
||||
|
||||
==> Pol: s
|
||||
|
||||
==> Temp: s
|
||||
|
||||
==> Tense: s
|
||||
|
||||
==> V: particle, prefix
|
||||
```
|
||||
|
||||
The categories `Ant`, `Pol`, `Temp` and `Tense` are as expected empty;
|
||||
there's no string to be added to the sentences, just a parameter that
|
||||
*chooses* the right forms of the clause.
|
||||
|
||||
`V` having empty fields `particle` and `prefix` is in this case just
|
||||
an artefact of a small lexicon: we happen to have no intransitive
|
||||
verbs with a particle or prefix in the core 300-word vocabulary. But a
|
||||
grammarian would know that it's still relevant to keep those fields,
|
||||
because in some bigger application such a verb may show up.
|
||||
|
||||
On the other hand, if some other field is always empty, it might be a
|
||||
hint for the grammarian to remove it altogether.
|
||||
|
||||
Example of equal fields:
|
||||
|
||||
```
|
||||
> gftest -g Lang -l Dut -q
|
||||
* Equal fields:
|
||||
==> RCl:
|
||||
s Pres Simul Pos Utr Pl
|
||||
s Pres Simul Pos Neutr Pl
|
||||
|
||||
==> RCl:
|
||||
s Pres Simul Neg Utr Pl
|
||||
s Pres Simul Neg Neutr Pl
|
||||
|
||||
==> RCl:
|
||||
s Pres Anter Pos Utr Pl
|
||||
s Pres Anter Pos Neutr Pl
|
||||
|
||||
==> RCl:
|
||||
s Pres Anter Neg Utr Pl
|
||||
s Pres Anter Neg Neutr Pl
|
||||
|
||||
==> RCl:
|
||||
s Past Simul Pos Utr Pl
|
||||
s Past Simul Pos Neutr Pl
|
||||
…
|
||||
```
|
||||
|
||||
Here we can see that in relative clauses, gender does not seem to play
|
||||
any role in plural. This could be a hint for the grammarian to make a
|
||||
leaner parameter type, e.g. `param RClAgr = SgAgr <everything incl. gender> | PlAgr <no gender here>`.
|
||||
|
||||
|
||||
### Unused fields: `-u`
|
||||
|
||||
These fields are not empty, but they are never used in the top
|
||||
category. The top category can be specified by `-s`, otherwise it is
|
||||
the default start category of the grammar.
|
||||
|
||||
Note that if you give a start category from very low, such as `Adv`,
|
||||
you get a whole lot of categories and fields that naturally have no
|
||||
way of ever making it into an adverb. So this is mostly meaningful to
|
||||
use for the start category.
|
||||
|
||||
|
||||
### Erased trees: `-r`
|
||||
|
||||
Show trees that are erased in some function, i.e. a function `F : A -> B -> C` has arguments A and B, but doesn't use one of them in the resulting tree of type C. This is usually a bug.
|
||||
|
||||
Example:
|
||||
|
||||
`gftest -g Lang -l "Dut Eng" -r`
|
||||
|
||||
output:
|
||||
```
|
||||
* Erased trees:
|
||||
|
||||
** RelCl (ExistNP something_NP) : RCl
|
||||
- Tree: AdvS (PrepNP with_Prep (RelNP (UsePron it_Pron) (UseRCl (TTAnt TPres ASimul) PPos (RelCl (ExistNP something_NP))))) (UseCl (TTAnt TPres ASimul) PPos (ExistNP something_NP))
|
||||
- Lin: ermee is er iets
|
||||
- Trans: with it, such that there is something, there is something
|
||||
|
||||
** write_V2 : V2
|
||||
- Tree: AdvS (PrepNP with_Prep (PPartNP (UsePron it_Pron) write_V2)) (UseCl (TTAnt TPres ASimul) PPos (ExistNP something_NP))
|
||||
- Lin: ermee is er iets
|
||||
- Trans: with it written there is something
|
||||
```
|
||||
|
||||
In the first result, an argument of type `RCl` is missing in the tree constructed by `RelNP`, and in the second result, the argument `write_V2` is missing in the tree constructed by `PPartNP`. In both cases, the English linearisation contains all the arguments, but in the Dutch one they are missing. (This bug is already fixed, just showing it here to demonstrate the feature.)
|
||||
|
||||
|
||||
### --show-coercions
|
||||
|
||||
First I'll explain what *coercions* are, then why it may be
|
||||
interesting to show them. Let's take a Spanish Foods grammar, and
|
||||
consider the category `Quality`—those `Good Pizza` and `Vegan Pizza`
|
||||
that you saw in the previous section. `Good`
|
||||
"bueno/buena/buenos/buenas" goes before the noun it modifies, whereas
|
||||
`Vegan` "vegano/vegana/…" goes after, so these will become different
|
||||
*concrete categories* in the PGF: `Quality_before` and
|
||||
`Quality_after`. (In reality, they are something like `Quality_7` and
|
||||
`Quality_8` though.)
|
||||
|
||||
Now, this difference is meaningful only when the adjective is modifying
|
||||
the noun: "la buena pizza" vs. "la pizza vegana". But when the
|
||||
adjective is in a predicative position, they both behave the same:
|
||||
"la pizza es buena" and "la pizza es vegana". For this, the grammar
|
||||
creates a *coercion*: both `Quality_before` and `Quality_after` may be
|
||||
treated as `Quality_whatever`. To save some redundant work, this coercion `Quality_whatever`
|
||||
appears in the type of predicative function, whereas the
|
||||
modification function has to be split into two different functions,
|
||||
one taking `Quality_before` and other `Quality_after`.
|
||||
|
||||
Now you know what coercions are, this is how it looks like in the program:
|
||||
|
||||
```
|
||||
> gftest -g Foods -l Spa --show-coercions
|
||||
* Coercions in the grammar:
|
||||
Quality_7--->_11
|
||||
Quality_8--->_11
|
||||
```
|
||||
|
||||
(Just mentally replace 7 with `before`, 8 with `after` and 11 with `whatever`.)
|
||||
|
||||
### --count-trees
|
||||
|
||||
Number of trees up to given size. Gives a number how many trees, and a
|
||||
couple of examples from the highest size. Examples:
|
||||
|
||||
```
|
||||
> gftest -g TestLang -l Eng --count-trees 10
|
||||
There are 675312 trees up to size 10, and 624512 of exactly size 10.
|
||||
For example:
|
||||
* AdvS today_Adv (UseCl (TTAnt TPres ASimul) PPos (ExistNP (UsePron i_Pron)))
|
||||
* UseCl (TTAnt TCond AAnter) PNeg (PredVP (SelfNP (UsePron they_Pron)) UseCopula)
|
||||
```
|
||||
|
||||
This counts the number of trees in the start category. You can also
|
||||
specify a category:
|
||||
|
||||
```
|
||||
> gftest -g TestLang -l Eng --count-trees 4 -s Adv
|
||||
There are 2409 trees up to size 4, and 2163 of exactly size 4.
|
||||
For example:
|
||||
* AdAdv very_AdA (PositAdvAdj young_A)
|
||||
* PrepNP above_Prep (UsePron they_Pron)
|
||||
```
|
||||
+62
-27
@@ -126,35 +126,70 @@ function draw_grammar_list() {
|
||||
function rmpublic(file) {
|
||||
return function() { remove_public(file,draw_grammar_list) }
|
||||
}
|
||||
publiclist.appendChild(wrap("h3",text("Public grammars")))
|
||||
if(files.length>0) {
|
||||
var unique_id=local.get("unique_id","-")
|
||||
var t=empty_class("table","grammar_list")
|
||||
for(var i in files) {
|
||||
var file=files[i].path
|
||||
var parts=file.split(/[-.]/)
|
||||
var basename=parts[0]
|
||||
var unique_name=parts[1]+"-"+parts[2]
|
||||
var mine = my_grammar(unique_name)!=null
|
||||
var del = mine
|
||||
? delete_button(rmpublic(file),"Don't publish this grammar")
|
||||
: []
|
||||
var tip = mine
|
||||
? "This is a copy of your grammar"
|
||||
: "Click to download a copy of this grammar"
|
||||
var modt=new Date(files[i].time)
|
||||
var fmtmodt=modt.toDateString()+", "+modt.toTimeString().split(" ")[0]
|
||||
var when=wrap_class("small","modtime",text(" "+fmtmodt))
|
||||
t.appendChild(edtr([td(del),
|
||||
td(title(tip,
|
||||
a(jsurl('open_public("'+file+'")'),
|
||||
[text(basename)]))),
|
||||
td(when)]))
|
||||
}
|
||||
publiclist.appendChild(t)
|
||||
var h=wrap("h3",text("Public grammars"))
|
||||
var ordermenu=wrap("select",[option("Newest first","byAge"),
|
||||
option("Alphabetical","byName")])
|
||||
ordermenu.value=local.get("publicOrder","byAge")
|
||||
ordermenu.onchange=function(){
|
||||
local.put("publicOrder",ordermenu.value)
|
||||
if(n>1) show_grammars()
|
||||
}
|
||||
var n=files.length
|
||||
var count=n==1 ? " (One grammar)" : " ("+n + " grammars)"
|
||||
var t=table(tr([td(h),td(text(count)),td(ordermenu)]))
|
||||
publiclist.appendChild(t)
|
||||
for(var i in files) {
|
||||
var file=files[i]
|
||||
file.t=new Date(file.time)
|
||||
file.s=file.t.getTime()
|
||||
}
|
||||
function sort_grammars() {
|
||||
switch(ordermenu.value) {
|
||||
case "byAge":
|
||||
files.sort((f1,f2)=>f2.s-f1.s)
|
||||
break;
|
||||
case "byName":
|
||||
files.sort((f1,f2)=>(f1.path>f2.path)-(f1.path<f2.path))
|
||||
}
|
||||
}
|
||||
var gt=empty_class("table","grammar_list")
|
||||
publiclist.appendChild(gt)
|
||||
function show_grammars() {
|
||||
clear(gt)
|
||||
if(files.length>0) {
|
||||
sort_grammars()
|
||||
var unique_id=local.get("unique_id","-")
|
||||
for(var i in files) {
|
||||
var file=files[i].path
|
||||
var parts=file.split(/[-.]/)
|
||||
var basename=parts[0]
|
||||
var unique_name=parts[1]+"-"+parts[2]
|
||||
var mine = my_grammar(unique_name)!=null
|
||||
var from_me = parts[1] == unique_id
|
||||
var del = from_me || mine
|
||||
? delete_button(rmpublic(file),"Remove this public grammar")
|
||||
: []
|
||||
var tip = mine
|
||||
? "This is a copy of your grammar"
|
||||
: "Click to download a copy of this grammar"
|
||||
var modt=new Date(files[i].time)
|
||||
var fmtmodt=modt.toDateString()+", "+modt.toTimeString().split(" ")[0]
|
||||
var when=wrap_class("small","modtime",text(" "+fmtmodt))
|
||||
gt.appendChild(edtr([td(del),
|
||||
td(title(tip,
|
||||
a(jsurl('open_public("'+file+'")'),
|
||||
[text(basename)]))),
|
||||
td(text(files[i].comment||"")),
|
||||
td(when)]))
|
||||
}
|
||||
}
|
||||
else
|
||||
publiclist.appendChild(p(text("No public grammars are available.")))
|
||||
// This is outside the table so it won't be cleared,
|
||||
// but show_grammars is only called once then there is less
|
||||
// than 2 grammars, so it's OK.
|
||||
}
|
||||
show_grammars()
|
||||
}
|
||||
if(navigator.onLine)
|
||||
gfcloud_public_json("ls-l",{},show_public,no_public)
|
||||
@@ -799,7 +834,7 @@ function draw_abstract(g) {
|
||||
}
|
||||
|
||||
function draw_comment(g) {
|
||||
return div_class("comment",editable("span",text(g.comment || ""),g,edit_comment,"Edit grammar description"));
|
||||
return div_class("comment",editable("span",text(g.comment || "…"),g,edit_comment,"Edit grammar description"));
|
||||
}
|
||||
|
||||
function module_name(g,ix) {
|
||||
|
||||
Reference in New Issue
Block a user